
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多这是一篇由Gerrit Meier撰写的客座博客,他来自Neo4j,负责维护Spring Data Neo4j模块。
几周前,Spring (for) GraphQL 发布了 1.2.0 版本,带来了一系列新功能。其中还包括与 Spring Data 模块的更佳集成。受这些变化的启发,我们在 Spring Data Neo4j 中增加了更多支持,以便在与 Spring GraphQL 结合使用时提供最佳体验。本文将指导您创建一个在 Neo4j 中存储数据并支持 GraphQL 的 Spring 应用程序。如果您只对领域部分感兴趣,可以愉快地跳过下一节;)
在此示例中,我选择深入 Fediverse。更具体地说,将 服务器 和 用户 放在重点。为什么选择这个领域,现在留给读者在接下来的段落中发现。
数据本身与可以从 Mastodon API 中获取的属性一致。为了简化数据集,数据是通过手动创建而不是获取 所有 数据。这使得数据集更容易检查。Cypher 导入语句如下所示
Cypher 导入
CREATE (s1:Server {
uri:'mastodon.social', title:'Mastodon', registrations:true,
short_description:'The original server operated by the Mastodon gGmbH non-profit'})
CREATE (meistermeier:Account {id:'106403780371229004', username:'meistermeier', display_name:'Gerrit Meier'})
CREATE (rotnroll666:Account {id:'109258442039743198', username:'rotnroll666', display_name:'Michael Simons'})
CREATE
(meistermeier)-[:REGISTERED_ON]->(s1),
(rotnroll666)-[:REGISTERED_ON]->(s1)
CREATE (s2:Server {
uri:'chaos.social', title:'chaos.social', registrations:false,
short_description:'chaos.social – a Fediverse instance for & by the Chaos community'})
CREATE (odrotbohm:Account {id:'108194553063501090', username:'odrotbohm', display_name:'Oliver Drotbohm'})
CREATE
(odrotbohm)-[:REGISTERED_ON]->(s2)
CREATE
(odrotbohm)-[:FOLLOWS]->(rotnroll666),
(odrotbohm)-[:FOLLOWS]->(meistermeier),
(meistermeier)-[:FOLLOWS]->(rotnroll666),
(meistermeier)-[:FOLLOWS]->(odrotbohm),
(rotnroll666)-[:FOLLOWS]->(meistermeier),
(rotnroll666)-[:FOLLOWS]->(odrotbohm)
CREATE
(s1)-[:CONNECTED_TO]->(s2)
运行语句后,图形成此形状。
数据集的图视图

值得注意的是,即使所有用户都关注彼此,Mastodon 服务器也只以一个方向连接。chaos.social 服务器上的用户无法搜索或浏览 mastodon.social 上的时间线。
免责声明:在此示例中,服务器的联合使用了非双向关系。
要跟进示例,您应该使用以下最低版本
最好访问 https://start.spring.io 并使用 Spring Data Neo4j 和 Spring GraphQL 依赖项创建一个新项目。如果您有点懒,也可以从此 链接 下载空的项目。
要 100% 跟随示例,您需要在系统中安装 Docker。如果您没有此选项或不想使用 Docker,可以使用 Neo4j Desktop 或纯 Neo4j Server 伪影进行本地部署,或作为托管选项 Neo4j Aura 或 空的 Neo4j Sandbox。稍后会有关于如何连接到手动启动的实例的说明。企业版不是必需的,社区版一切都能正常工作。
在此示例中,大部分配置工作将由 Spring Boot 自动配置完成。无需手动设置 bean。有关幕后发生情况的更多信息,请参阅 Spring for GraphQL 文档。稍后将引用文档的特定部分。
首先要做的就是对领域类进行建模。如导入中所示,只有 Servers 和 Accounts。
账户领域类
@Node
public class Account {
@Id String id;
String username;
@Property("display_name") String displayName;
@Relationship("REGISTERED_ON") Server server;
@Relationship("FOLLOWS") List<Account> following;
// constructor, etc.
}
可以合理地假设,ID 是(服务器)唯一的。
Server 中的几行中,使用 @Property 将数据库字段 display_name 映射到 Java 实体中的驼峰式命名 displayName。服务器领域类
@Node
public class Server {
@Id String uri;
String title;
@Property("registrations") Boolean registrationsAllowed;
@Property("short_description") String shortDescription;
@Relationship("CONNECTED_TO") List<Server> connectedServers;
// constructor, etc.
}
有了这些实体类,就可以创建 AccountRepository。
账户存储库
@GraphQlRepository
public interface AccountRepository extends Neo4jRepository<Account, String> { }
有关为何使用此注解的详细信息稍后将提供。此处包含接口的完整性。
要连接到 Neo4j 实例,需要在 application.properties 文件中添加连接参数。
spring.neo4j.uri=neo4j://:7687
spring.neo4j.authentication.username=neo4j
spring.neo4j.authentication.password=verysecret
如果尚未完成,可以启动数据库并运行上面的 Cypher 语句来设置数据。在本文的后续部分,将使用 Neo4j-Migrations 来确保数据库始终处于所需状态。
在研究 Spring Data 和 Spring for GraphQL 的集成功能之前,应用程序将使用带有 @Controller 样板批注的类进行设置。该控制器将由 Spring for GraphQL 注册为 accounts 查询的 DataFetcher。
@Controller
class AccountController {
private final AccountRepository repository;
AccountController(AccountRepository repository) {
this.repository = repository;
}
@QueryMapping
List<Account> accounts() {
return repository.findAll();
}
}
定义一个 GraphQL schema,该 schema 不仅定义了我们的实体,还定义了与控制器中的方法名(accounts)同名的查询。
type Query {
accounts: [Account]!
}
type Account {
id: ID!
username: String!
displayName: String!
server: Server!
following: [Account]
lastMessage: String!
}
type Server {
uri: ID!
title: String!
shortDescription: String!
connectedServers: [Server]
}
此外,为了方便地浏览 GraphQL 数据,应在 application.properties 中启用 GraphiQL。这是开发时的一个有用工具。通常应禁用此设置以用于生产部署。
spring.graphql.graphiql.enabled=true
如果一切都已按照上述描述设置好,就可以使用 ./mvnw spring-boot:run 启动应用程序。访问 https://:8080/graphiql?path=/graphql 将会显示 GraphiQL 浏览器。
在 GraphiQL 中查询
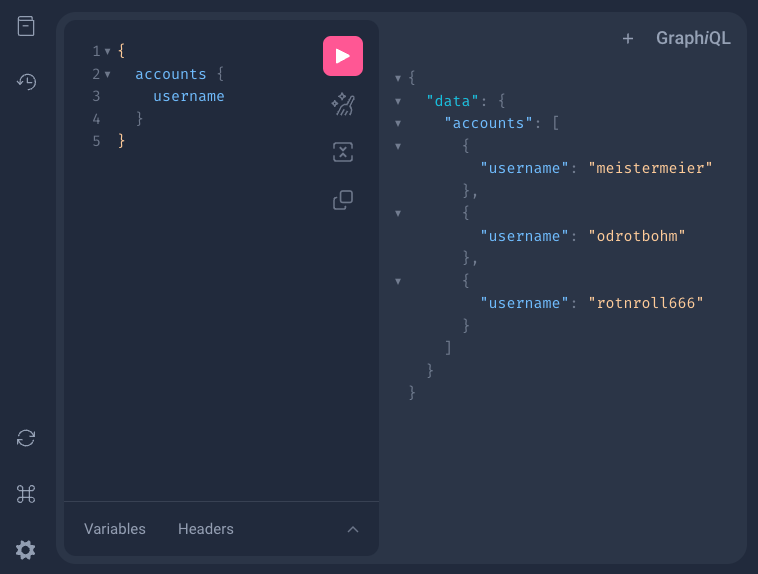
为了验证 accounts 方法是否正常工作,向应用程序发送一个 GraphQL 请求。
第一个 GraphQL 请求
{
accounts {
username
}
}
并且预期的答案从服务器返回。
GraphQL 响应
{
"data": {
"accounts": [
{
"username": "meistermeier"
},
{
"username": "rotnroll666"
},
{
"username": "odrotbohm"
}
]
}
}
当然,控制器中的方法可以通过添加参数来调整,使用 @Argument 来处理参数,或者获取请求的字段(此处为 accounts.username)以减少通过网络传输的数据量。在前面的示例中,存储库将获取给定领域实体的所有属性,包括所有关系。这些数据将在很大程度上被丢弃,以便只向用户返回 username。
此示例应能让您对 Annotated Controllers 的功能有一个初步了解。通过添加 Spring Data Neo4j 的查询生成和映射功能,就创建了一个(简单的)GraphQL 应用程序。
但此时,这两个库似乎在这个应用程序中并行存在,而不是真正集成。SDN 和 Spring for GraphQL 如何才能真正结合起来?
作为第一步,可以删除 AccountController 中的 accounts 方法。重新启动应用程序并使用上面的请求再次查询它,仍然会得到相同的结果。
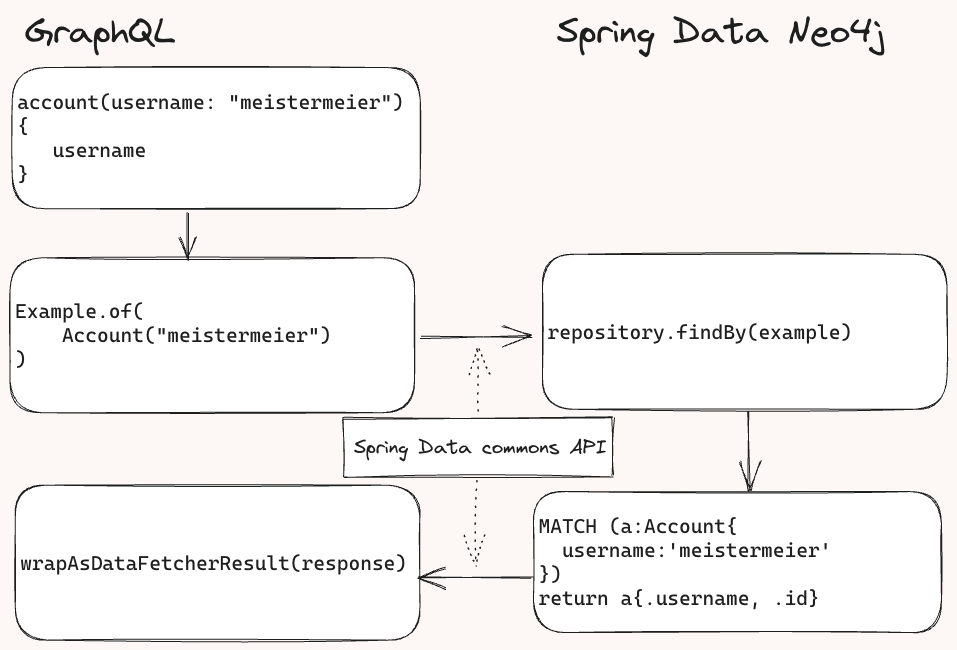
这样做是因为 Spring for GraphQL 识别出 GraphQL schema 中的结果类型(Account 的数组)。它会扫描符合条件的 Spring Data 存储库,这些存储库必须扩展 QueryByExampleExecutor 或 QuerydslPredicateExecutor(在此博客文章中未包含)。在此示例中,AccountRepository 已被隐式标记为 QueryByExampleExecutor,因为它扩展了 Neo4jRespository,而后者已经定义了执行器。@GraphQlRepository 注解使 Spring for GraphQL 知道该存储库可以并且应该用于查询(如果可能)。
在不更改实际代码的情况下,可以在 schema 中定义第二个查询字段。这次应该按用户名过滤结果。乍一看,用户名看起来是唯一的,但在 Fediverse 中,这只对给定的实例有效。多个实例可能具有相同的用户名。为了尊重这种行为,查询应该能够返回一个 Accounts 数组。
关于 query by example (Spring Data commons) 的文档提供了关于此机制内部工作原理的更多详细信息。
更新的查询类型
type Query {
account(username: String!): [Account]!
重新启动应用程序后,现在可以交互式地将用户名添加为查询的参数。
查询具有相同用户名的账户数组
{
account(username: "meistermeier") {
username
following {
username
server {
uri
}
}
}
}
显然,只有 Account 具有此用户名。
按用户名查询的响应
{
"data": {
"account": [
{
"username": "meistermeier",
"following": [
{
"username": "rotnroll666",
"server": {
"uri": "mastodon.social"
}
},
{
"username": "odrotbohm",
"server": {
"uri": "chaos.social"
}
}
]
}
]
}
}
在后台,Spring for GraphQL 将字段作为参数添加到传递给存储库的示例对象中。Spring Data Neo4j 然后检查示例,为 Cypher 查询创建匹配条件,执行它,并将结果发送回 Spring GraphQL 进行进一步处理,将结果塑造成正确的响应格式。
(示意图)API 调用流程
尽管示例数据集并不庞大,但通常最好具有适当的功能来分块请求结果数据。Spring for GraphQL 使用 Cursor Connections 规范。
包含所有类型的完整 schema 规范如下所示。
带有游标连接的 Schema
type Query {
accountScroll(username:String, first: Int, after: String, last: Int, before:String): AccountConnection
}
type AccountConnection {
edges: [AccountEdge]!
pageInfo: PageInfo!
}
type AccountEdge {
node: Account!
cursor: String!
}
type PageInfo {
hasPreviousPage: Boolean!
hasNextPage: Boolean!
startCursor: String
endCursor: String
}
type Account {
id: ID!
username: String!
displayName: String!
server: Server!
following: [Account]
lastMessage: String!
}
type Server {
uri: ID!
title: String!
shortDescription: String!
connectedServers: [Server]
}
尽管我个人喜欢拥有一个完整的有效 schema,但也可以在定义中跳过所有游标连接特定的部分。仅带有 AccountConnection 定义的查询就足以让 Spring for GraphQL 推导并填充缺失的部分。参数的读取方式如下:
first:要获取的数据量(如果没有默认值)after:数据应在之后获取的滚动位置last:在 before 位置之前要获取的数据量before:数据应获取到的(不包含)滚动位置还有一个问题:结果集按什么顺序返回?在这种情况下,稳定的排序顺序是必须的,否则无法保证数据库以可预测的顺序返回数据。存储库还需要扩展 QueryByExampleDataFetcher.QueryByExampleBuilderCustomizer 并实现 customize 方法。在那里也可以为查询添加默认限制,在本例中为 1,以演示分页。
已添加排序顺序(和限制)
@GraphQlRepository
interface AccountRepository extends Neo4jRepository<Account, String>,
QueryByExampleDataFetcher.QueryByExampleBuilderCustomizer<Account>
{
@Override
default QueryByExampleDataFetcher.Builder<Account, ?> customize(QueryByExampleDataFetcher.Builder<Account, ?> builder) {
return builder.sortBy(Sort.by("username"))
.defaultScrollSubrange(new ScrollSubrange(ScrollPosition.offset(), 1, true));
}
}
应用程序重新启动后,现在可以调用第一个分页查询。
第一个元素的 Pagination
{
accountScroll {
edges {
node {
username
}
}
pageInfo {
hasNextPage
endCursor
}
}
}
为了获得用于进一步交互的元数据,还请求了 pageInfo 的一部分。
第一个元素的结果
{
"data": {
"accountScroll": {
"edges": [
{
"node": {
"username": "meistermeier"
}
}
],
"pageInfo": {
"hasNextPage": true,
"endCursor": "T18x"
}
}
}
}
现在可以使用 endCursor 进行下一次交互。使用此值作为 after 的值,并将限制设置为 2 来查询应用程序...
最后一个元素的 Pagination
{
accountScroll(after:"T18x", first: 2) {
edges {
node {
username
}
}
pageInfo {
hasNextPage
endCursor
}
}
}
...结果是最后一个(或最后几个)元素。此外,没有下一页的标记(hasNextPage=false)表明分页已到达数据集的末尾。
最后一个元素的结果
{
"data": {
"accountScroll": {
"edges": [
{
"node": {
"username": "odrotbohm"
}
},
{
"node": {
"username": "rotnroll666"
}
}
],
"pageInfo": {
"hasNextPage": false,
"endCursor": "T18z"
}
}
}
}
也可以通过使用定义的 last 和 before 参数向后滚动数据。此外,完全可以将此滚动与已知的 query by example 功能相结合,并在 GraphQL schema 中定义一个也接受 Account 字段作为过滤条件的查询。
带分页的过滤器
accountScroll(username:String, first: Int, after: String, last: Int, before:String): AccountConnection
使用 GraphQL 的一个主要优点是引入联合数据的选项。简而言之,这意味着应用程序数据库中存储的数据可以被丰富,如本例所示,可以从远程系统/微服务/...
可以通过利用已定义的控制器来实现这种数据联合。
用于联合数据的 SchemaMapping
@Controller
class AccountController {
@SchemaMapping
String lastMessage(Account account) {
var id = account.getId();
String serverUri = account.getServer().getUri();
WebClient webClient = WebClient.builder()
.baseUrl("https://" + serverUri)
.build();
return webClient.get()
.uri("/api/v1/accounts/{id}/statuses?limit=1", id)
.exchangeToMono(clientResponse ->
clientResponse.statusCode().equals(HttpStatus.OK)
? clientResponse
.bodyToMono(String.class)
.map(AccountController::extractData)
: Mono.just("could not retrieve last status")
)
.block();
}
}
在 schema 中向 Account 添加 lastMessage 字段并重新启动应用程序,现在就有选项来查询带有此附加信息的账户了。
带联合数据的查询
{
accounts {
username
lastMessage
}
}
带联合数据的响应
{
"data": {
"accounts": [
{
"username": "meistermeier",
"lastMessage": "@taseroth erst einmal schauen, ob auf die Aussage auch Taten folgen ;)"
},
{
"username": "odrotbohm",
"lastMessage": "Some #jMoleculesp/#SpringCLI integration cooking to easily add the former[...]"
},
{
"username": "rotnroll666",
"lastMessage": "Werd aber das Rad im Rückwärts-Turbo schon irgendwie vermissen."
}
]
}
}
再次查看控制器,可以清楚地看到数据检索现在是一个瓶颈。对于每个 Account,都会发出一个接一个的请求。但是,Spring for GraphQL 有助于改善每个 Account 的顺序请求情况。解决方案是在 lastMessage 字段上使用 @BatchMapping,而不是 @SchemaMapping。
用于联合数据的 BatchMapping
@Controller
public class AccountController {
@BatchMapping
public Flux<String> lastMessage(List<Account> accounts) {
return Flux.concat(
accounts.stream().map(account -> {
var id = account.getId();
String serverUri = account.getServer().getUri();
WebClient webClient = WebClient.builder()
.baseUrl("https://" + serverUri)
.build();
return webClient.get()
.uri("/api/v1/accounts/{id}/statuses?limit=1", id)
.exchangeToMono(clientResponse ->
clientResponse.statusCode().equals(HttpStatus.OK)
? clientResponse
.bodyToMono(String.class)
.map(AccountController::extractData)
: Mono.just("could not retrieve last status")
);
}).toList());
}
}
为了进一步改善这种情况,建议也为结果引入适当的缓存。联合数据可能不需要在每次请求时都获取,而只在一定时间后刷新。
Neo4j-Migrations 是一个将迁移应用于 Neo4j 的项目。为了确保数据库中始终存在干净的数据状态,提供了一个初始 Cypher 语句。其内容与本文开头的 Cypher 代码片段相同。事实上,内容直接包含在此文件中。
通过提供 Spring Boot 启动器将 Neo4j-Migrations 放入类路径,它将运行默认文件夹(resources/neo4j/migrations)中的所有迁移。
Neo4j-Migrations 依赖定义
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-spring-boot-starter</artifactId>
<version>${neo4j-migrations.version}</version>
<scope>test</scope>
</dependency>
Spring Boot 3.1 带来了 Testcontainers 的新功能。其中一项功能是自动设置属性,无需定义 @DynamicPropertySource。在测试执行期间,容器启动后,(Spring Boot 已知的)属性将被填充。
首先,需要在 pom.xml 文件中添加 Testcontainers Neo4j 的依赖定义。
Testcontainers 依赖定义
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>neo4j</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>junit-jupiter</artifactId>
<scope>test</scope>
</dependency>
为了使用 Testcontainers Neo4j,将创建一个容器定义接口。
容器配置
interface Neo4jContainerConfiguration {
@Container
@ServiceConnection
Neo4jContainer<?> neo4jContainer = new Neo4jContainer<>(DockerImageName.parse("neo4j:5"))
.withRandomPassword()
.withReuse(true);
}
然后可以使用 @ImportTestContainers 注解在(集成)测试类中使用它。
用 @ImportTestContainers 注解的测试
@SpringBootTest
@ImportTestcontainers(Neo4jContainerConfiguration.class)
class Neo4jGraphqlApplicationTests {
final GraphQlTester graphQlTester;
@Autowired
public Neo4jGraphqlApplicationTests(ExecutionGraphQlService graphQlService) {
this.graphQlTester = ExecutionGraphQlServiceTester.builder(graphQlService).build();
}
@Test
void resultMatchesExpectation() {
String query = "{" +
" account(username:\"meistermeier\") {" +
" displayName" +
" }" +
"}";
this.graphQlTester.document(query)
.execute()
.path("account")
.matchesJson("[{\"displayName\":\"Gerrit Meier\"}]");
}
}
为了完整性,此类还包括 GraphQlTester 和一个测试应用程序 GraphQL API 的示例。
现在也可以直接从测试文件夹运行整个应用程序并使用 Testcontainers 镜像。
从测试类使用容器启动应用程序
@TestConfiguration(proxyBeanMethods = false)
class TestNeo4jGraphqlApplication {
public static void main(String[] args) {
SpringApplication.from(Neo4jGraphqlApplication::main)
.with(TestNeo4jGraphqlApplication.class)
.run(args);
}
@Bean
@ServiceConnection
Neo4jContainer<?> neo4jContainer() {
return new Neo4jContainer<>("neo4j:5").withRandomPassword();
}
}
@ServiceConnection 注解还负责使从测试类启动的应用程序知道容器正在运行的坐标(连接字符串、用户名、密码等)。
要在 IDE 外部启动应用程序,现在也可以调用 ./mvnw spring-boot:test-run。如果测试文件夹中只有一个带有 main 方法的类,它将被启动。
与 QueryByExampleExecutor 并行,Spring Data Neo4j 模块支持 QuerydslPredicateExecutor。要使用它,存储库需要扩展 CrudRepository 而不是 Neo4jRepository,并将其声明为给定类型的 QuerydslPredicateExecutor。添加对滚动/分页的支持还需要添加 QuerydslDataFetcher.QuerydslBuilderCustomizer 并实现其 customize 方法。
本文介绍的整个基础设施也适用于响应式堆栈。基本上,将所有内容都加上 Reactive... 前缀(如 ReactiveQuerybyExampleExecutor)将使其成为一个响应式应用程序。
最后但并非最不重要的一点是,这里使用的滚动机制基于 OffsetScrollPosition。还有一个 KeysetScrollPosition 可用。它利用排序属性与定义 ID 结合使用。
@Override
default QueryByExampleDataFetcher.Builder<Account, ?> customize(QueryByExampleDataFetcher.Builder<Account, ?> builder) {
return builder.sortBy(Sort.by("username"))
.defaultScrollSubrange(new ScrollSubrange(ScrollPosition.keyset(), 1, true));
}
很高兴看到 Spring Data 模块中的便捷方法不仅为用户的用例提供了更广泛的可访问性,而且还被其他 Spring 项目用来减少需要编写的代码量。这使得现有代码库的维护量减少,并有助于关注业务问题而不是基础设施。
这篇帖子有点长,因为我明确希望至少触及查询被调用时发生的事情的表面,而不仅仅是谈论神奇的结果。
请继续探索可能实现的功能以及应用程序对不同类型查询的行为。在一篇博文中涵盖所有可用主题和功能几乎是不可能的。
祝您 GraphQL 编码和探索愉快。您可以在 GitHub 上找到示例项目,地址为 https://github.com/meistermeier/spring-graphql-neo4j。