
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多作者:Mark Pollack 博士、Christian Tsolov 和 Josh Long
嗨,Spring 粉丝们!Spring AI 已在 Spring Initializr 和其他任何可以找到优质字节的地方上线。咨询您的医生,看看 AI 是否适合您!作为 Java 和 Spring 开发者,现在是一个激动人心的时刻。从来没有比现在更好的时机成为 Java 和 Spring 开发者,在这个独特的 AI 时刻更是如此。您看,人们谈论 AI 工程时,90% 的内容都只是与模型的集成,其中大多数模型都有 HTTP API。而这些模型接收的大多数内容都只是人类语言的 String。这是集成代码,还有什么地方比您的基于 Spring 的工作负载的侧面更适合这些集成存在呢?这些工作负载的业务逻辑驱动着您的组织,并守护着为您的组织提供数据的数据。
AI 很棒,但它并不完美。和所有技术一样,它也有问题!有一些事情需要注意,当您探索 Spring AI 时,要知道您正在根据支持您走向生产的模式进行探索。让我们看看其中的一些。
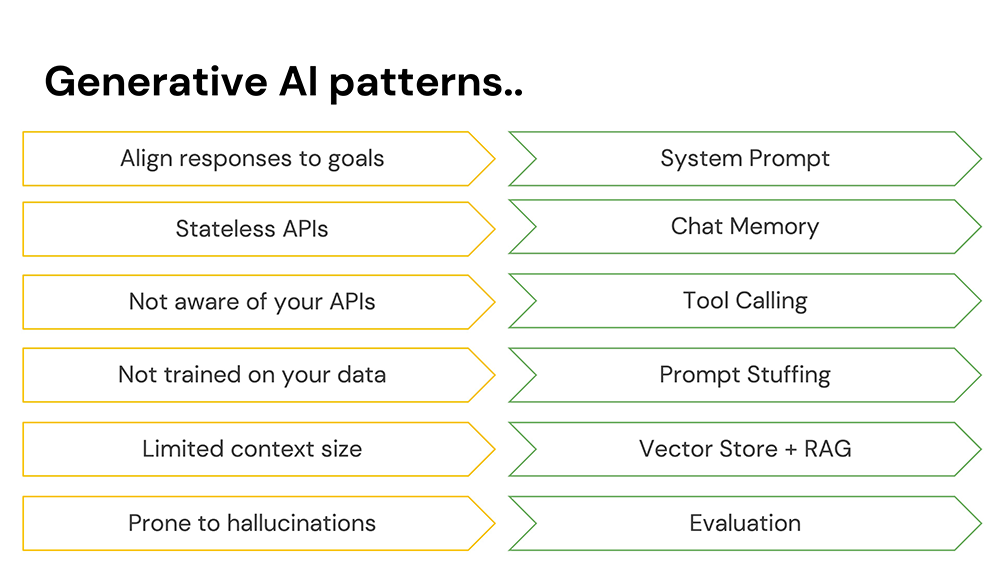
聊天模型几乎可以处理任何事情,并且会跟随您进入任何死胡同。如果您希望它专注于某个特定任务,请给它一个系统提示。
模型是无状态的。如果您曾经通过 ChatGPT 或 Claude Desktop 处理过模型,您可能会觉得这很奇怪,因为它们会在每个后续请求中提交所有已说过内容的副本。这份副本会提醒模型已经说过什么。这份副本就是聊天记忆。
模型生活在一个隔离的沙盒中。这很合理!我们都看过名为《终结者》的纪录片,知道失控的 AI 会出什么问题。但是,如果您通过工具调用给它们一点控制权,它们可以做很多令人惊奇的事情。
模型相当聪明,但并非无所不知!您可以在请求正文中提供数据,以帮助它们更好地回应。这称为提示填充。
但是不要发送太多数据!相反,只发送与当前查询相关的数据。您可以通过将数据放入向量存储来支持查找彼此相似的记录。然后,进行检索增强生成 (RAG),即您将从向量存储中筛选出的结果子集发送给模型进行最终分析。
聊天模型喜欢聊天,即使它们是错的。这有时会产生有趣且不正确的结果,称为幻觉。使用评估器来验证响应基本上符合您的预期。
Spring AI 是一个巨大的飞跃,但对于 Spring 开发者来说,它会感觉像是一个自然的下一步。它的工作方式与任何 Spring 项目一样。它具有可移植的服务抽象,让您可以一致且方便地使用多种模型。它提供 Spring Boot Starter、配置属性和自动配置。而且,Spring AI 传承了 Spring Boot 以生产为导向的理念,支持虚拟线程、GraalVM 原生镜像以及通过 Micrometer 实现的可观察性。它还提供出色的开发者体验,集成了 Spring Boot 的 DevTools,并为 Docker Compose 和 Testcontainers 提供了丰富的支持。与所有 Spring 项目一样,您可以从 Spring Initializr 开始。
我们就是要这么做!我们要构建一个支持领养狗的应用程序!我受到 2021 年一只走红的狗的启发。那只名叫 Prancer 的狗听起来真是个麻烦!这是我最喜欢的广告节选:
“好吧,我试过了。过去几个月我一直在努力发布这只狗的领养信息,并试图让它听起来……好一点。问题是,它就是不好。像小妖精一样神经质、厌男、厌动物、厌孩子的狗的市场并不大。但我必须相信 Prancer 也有它的归宿,因为我已经累了,我的家人也累了。我们每天都生活在它在我们家中创造的恶魔般的吉娃娃地狱中。”
听起来真是个麻烦!但即使是脾气暴躁的狗也值得拥有充满爱的家园。所以让我们构建一个服务,让人们与他们梦想(或噩梦?)中的狗团聚。访问 Spring Initializr 并将以下依赖项添加到您的项目中:PgVector, GraalVM Native Support, Actuator, Data JDBC, JDBC Chat Memory, PostgresML, Devtools 和 Web。选择 Java 24(或更高版本)和 Apache Maven 作为构建工具。(严格来说,这里没有理由不能使用 Gradle,但示例将以 Apache Maven 为准)确保工件名为 adoptions。
请确保您的 pom.xml 中也包含:org.springframework.ai:spring-ai-advisors-vector-store。
其中一些东西是熟悉的。Data JDBC 只是引入了 Spring Data JDBC,它只是一个 ORM 映射器,允许您与 SQL 数据库进行通信。Web 引入了 Spring MVC。Actuator 引入了 Spring Boot 的可观察性堆栈,部分由 Micrometer 提供支持。Devtools 是一个开发时功能,允许您在更改时进行实时重载。每次您在 Visual Studio Code 或 Eclipse 中执行“保存”操作时,它都会自动重新加载代码,并且每次您从 IntelliJ IDEA 切换出去时,它都会自动启动。GraalVM Native Support 引入了对 OpenJDK 分支 GraalVM 的支持,该分支除其他功能外,还提供了一个预编译 (AOT) 编译器,可生成轻量级、快速的二进制文件。
我们说过 Spring Data JDBC 将使连接到 SQL 数据库变得容易,但是哪一个呢?在我们的应用程序中,我们将使用 PostgreSQL,但不仅仅是普通的 PostgresSQL!我们将加载两个非常重要的扩展:vector 和 postgresml。vector 插件允许 PostgresSQL 充当向量存储。您需要将任意(文本、图像、音频)数据转换为嵌入,然后才能持久化。为此,您需要一个嵌入模型。PostgresML 在这里提供了该功能。这些关注点通常是正交的——PostgreSQL 能够同时完成这两个任务非常方便。构建 Spring AI 应用程序的一个重要部分是决定您将使用哪个向量存储、嵌入模型和聊天模型。
当然,我们今天要使用的是 Claude 聊天模型。要连接到它,您需要一个 API 密钥。您可以从 Anthropic 开发者门户获取一个。Claude 非常适合大多数企业工作负载。在不确定或敏感的环境中,它通常更礼貌、稳定和保守。这使其成为企业应用程序的绝佳选择。Claude 在文档理解和遵循多步骤指令方面也表现出色。
正如我之前所说,我们将使用 PostgreSQL。获取一个支持 vector 和 postgresml 的 Docker 镜像并不太难。我提供了一个文件 adoptions/db/run.sh。运行它。它将启动一个 Docker 镜像。然后您需要使用一个应用程序用户对其进行初始化。运行 adoptions/db/init.sh。
现在您已万事俱备。
在 application.properties 中指定所有与数据库连接相关的信息。
spring.sql.init.mode=always
#
spring.datasource.url=jdbc:postgresql://:5433/postgresml
spring.datasource.username=myappuser
spring.datasource.password=mypassword
#
spring.ai.postgresml.embedding.create-extension=true
spring.ai.postgresml.embedding.options.vector-type=pg_vector
#
spring.ai.vectorstore.pgvector.dimensions=768
spring.ai.vectorstore.pgvector.initialize-schema=true
#
spring.ai.chat.memory.repository.jdbc.initialize-schema=always
这里我们指定了我们想要的向量类型,是否希望 Spring AI 初始化 PostgresML 扩展。我们指定了存储在 PostgreSQL 中的向量所需的维度,以及是否希望 Spring AI 初始化将其用作向量存储所需的模式。
我们还希望将一些数据(狗!)安装到数据库中,因此我们将告诉 Spring Boot 运行 schema.sql 和 data.sql,它们分别在数据库中创建表并安装数据。
我们需要与刚刚创建的 dog 表进行通信,所以我们有一个 Spring Data JDBC 实体和仓库。将以下类型添加到 AdoptionsApplication.java 的底部,在最后一个 } 之后。
interface DogRepository extends ListCrudRepository<Dog, Integer> {
}
record Dog(@Id int id, String name, String owner, String description ){
}
我们将通过 HTTP 控制器处理用户的提问。这是骨架定义:
@Controller
@ResponseBody
class AdoptionsController {
private final ChatClient ai;
AdoptionsController (ChatClient.Builder ai ) {
this.ai = ai.build();
}
@GetMapping("/{user}/assistant")
String inquire(@PathVariable String user, @RequestParam String question) {
return ai
.prompt()
.user(question)
.call()
.content();
}
}
所以,基本上,我们可以通过向 :8080/youruser/assistant 发送 HTTP 请求来提问。试一试。
http :8080/jlong/assistant question=="my name is Josh"
您应该会得到一个热情洋溢的回复。听起来我们是朋友!
让我们来考验一下这份友谊。
http :8080/jlong/assistant question=="what's my name?"
在我的测试中,我失望地发现 Claude 已经把我忘了。它完全不记得我了!让我们给我们的模型一些记忆。我们将使用一个名为 PromptChatMemoryAdvisor 的顾问来完成这项工作,它会在请求模型之前和之后进行预处理和后处理。将其定义添加到 AdoptionsApplication 中。
@Bean
PromptChatMemoryAdvisor promptChatMemoryAdvisor(DataSource dataSource) {
var jdbc = JdbcChatMemoryRepository
.builder()
.dataSource(dataSource)
.build();
var chatMessageWindow = MessageWindowChatMemory
.builder()
.chatMemoryRepository(jdbc)
.build();
return PromptChatMemoryAdvisor
.builder(chatMessageWindow)
.build();
}
Advisors 就像过滤器或拦截器。它们是向请求正文添加内容或以通用、横切的方式处理响应的好方法。有点像 Spring 的面向切面编程支持。
此顾问将为您保留消息。在这种情况下,它将使用我们已经告诉 Spring AI 初始化的模式 (spring.ai.chat.memory.repository.jdbc.initialize-schema=always) 将其持久化到我们的 PostgreSQL 数据库中。
更改 ChatClient 的配置
// ..
AdoptionsController (PromptChatMemoryAdvisor promptChatMemoryAdvisor,
ChatClient.Builder ai ) {
this.ai = ai
.defaultAdvisors(promptChatMemoryAdvisor)
.build();
}
// ..
为了让 PromptChatMemoryAdvisor 工作,它需要某种方式将您的请求与给定的对话关联起来。您可以通过在请求中分配一个对话 ID 来实现这一点。修改 inquire 方法。
@GetMapping("/{user}/assistant")
String inquire(@PathVariable String user, @RequestParam String question) {
return ai
.prompt()
.user(question)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, user)) // new
.call()
.content();
}
在此示例中,我们只是使用 URL 中的路径变量来创建不同的对话。当然,更合适的方法可能是使用 Spring Security 认证的 Principal#getName() 调用。如果安装了 Spring Security,您可以将认证的主体作为控制器方法的参数注入。
重新启动程序,然后重新运行相同的 HTTP 交互,这次您应该会发现模型记住了您。注意:您可以通过删除该特定表中的数据来随时重置记忆。
太好了!如果你只是构建了一个快速 UI,那么你实际上就拥有了自己的 Claude Desktop。但这并不是我们真正想要的。记住,我们正在努力帮助人们从我们虚构的狗狗领养机构 Pooch Palace 领养狗。我们不希望人们从我们的助手那里做作业或获得编码帮助。让我们通过配置一个系统提示来为我们的模型设定一个任务声明。再次更改配置。
// ..
AdoptionsController (PromptChatMemoryAdvisor promptChatMemoryAdvisor,
ChatClient.Builder ai ) {
var system = """
You are an AI powered assistant to help people adopt a dog from the adoption agency named Pooch Palace with locations in Rio de Janeiro, Mexico City, Seoul, Tokyo, Singapore, New York City, Amsterdam, Paris, Mumbai, New Delhi, Barcelona, London, and San Francisco. Information about the dogs available will be presented below. If there is no information, then return a polite response suggesting we don't have any dogs available.
""";
this.ai = ai
.defaultSystem(system)
// ..
.build();
}
// ..
让我们尝试提一个更相关的问题
http :8080/jlong/assistant question=="do you have any neurotic dogs?"
我们希望模型能知道我们的朋友 Prancer。但它会回答说不知道。
我们尚未将对 SQL 数据库的访问权限扩展到模型(目前还没有)。我们可以读取所有数据库,然后将它们全部连接到请求的正文中。从概念上讲,假设我们有足够小的数据集和足够大的令牌计数,这会奏效。但这是原则问题!请记住,所有与模型的交互都会产生令牌成本。这种成本可能以美元和美分的形式承担,例如在使用 Claude 等托管多租户 LLM 时,或者至少是以复杂性(CPU 和 GPU 资源消耗)成本的形式承担。无论哪种方式:我们都希望尽可能降低这些成本。
借助 Spring AI 与 Actuator 模块的集成,您可以并且应该密切关注令牌消耗。在您的 application.properties 中添加以下内容:
management.endpoints.web.exposure.include=*
management.endpoint.health.show-details=always
重启应用程序,然后向模型发送一些请求。然后导航到浏览器中的 localhost:8080/actuator/metrics,您应该会看到以 gen_ai 开头的指标,例如:gen_ai.client.token.usage。在此处获取有关该指标的详细信息:localhost:8080/actuator/metrics/gen_ai.client.token.usage。指标集成由出色的 Micrometer 项目提供支持,该项目集成了几乎所有时间序列数据库,包括 Prometheus、Graphite、Netflix Atlas、DataDog、Dynatrace 等。因此,您也可以将这些指标发布到这些 TSDB,以帮助为操作构建最重要的单一视图体验。
使用新创建的 DogRepository 从 SQL 数据库中读取所有数据,然后在构造函数中将 Spring AI Document 写入 VectorStore。
//...
AdoptionsController(JdbcClient db,
PromptChatMemoryAdvisor promptChatMemoryAdvisor,
ChatClient.Builder ai,
DogRepository repository,
VectorStore vectorStore) {
var count = db
.sql("select count(*) from vector_store")
.query(Integer.class)
.single();
if (count == 0) {
repository.findAll().forEach(dog -> {
var dogument = new Document("id: %s, name: %s, description: %s".formatted(
dog.id(), dog.name(), dog.description()
));
vectorStore.add(List.of(dogument));
});
}
// ... same as before
}
这里没有什么特别的方案。我们正在编写一个包含一些字符串数据的 Document。字符串中的内容无关紧要。
这将使用 PostgresML 在后台完成工作。我们必须配置一个 QuestionAnswerAdvisor,以便 ChatClient 知道在将请求发送到模型进行最终分析之前,会咨询向量存储以获取支持文档(“狗文档”?)。相应地修改构造函数中稍后的 ChatClient 定义。
this.ai = ai
// ...
.defaultAdvisors(promptChatMemoryAdvisor,
new QuestionAnswerAdvisor(vectorStore))
// ...
.build();
重新运行关于神经质狗的请求,您应该会发现,确实有一只神经质的狗,它可能正是医生所需要的,它的名字叫 Prancer!太棒了!
注意:我们一直以字符串形式获取响应,但这并不是构建抽象的基础!我们需要一个强类型对象,可以在我们的代码库中传递。如果您愿意,可以让模型将返回数据映射到这样一个强类型对象。假设您有以下记录:
record DogAdoptionSuggestion(int id,String name, String description) {}
我们可以使用 entity(Class<?>) 方法而不是 content() 方法。
//
@GetMapping("/{user}/assistant")
DogAdoptionSuggestion inquire (...) {
return ai
.prompt()
.user(..) //
.entity(DogAdoptionSuggestion.class);
}
你会得到一个强类型对象。怎么做到的?魔法!(我想。)总之,你可以这样做,但我们将继续使用 content(),毕竟我们正在构建一个聊天机器人。
所以,我们与梦想中的狗狗重逢了!现在怎么办?好吧,对于任何热血人类来说,下一步自然是想领养那只狗狗,对吧!但还有日程安排要做。让我们允许模型通过访问工具来与我们正在申请专利的、行业领先的调度算法进行集成。
将以下类型添加到代码页底部
@Component
class DogAdoptionScheduler {
@Tool(description = "schedule an appointment to pickup or adopt a " +
"dog from a Pooch Palace location")
String schedule(int dogId, String dogName) {
System.out.println("Scheduling adoption for dog " + dogName);
return Instant
.now()
.plus(3, ChronoUnit.DAYS)
.toString();
}
}
这只是一个普通的 Spring bean。我们宣布此方法已被调用,然后返回一个硬编码为未来三天的日期。重要的是,我们有一个方法可供模型使用,并用 @Tools 注解。重要的是,这些工具的描述使用人类语言散文,尽可能具有描述性。还记得你妈妈说“用你的话!”吗?她就是这个意思!它将帮助你成为一名更好的 AI 工程师(更不用说一个更好的队友了,但那个讨论是另一回事了……)。
请务必通过将其指向工具来更新 ChatClient 配置。
AdoptionsController(
JdbcClient db,
DogAdoptionScheduler scheduler,
ChatClient.Builder ai,
DogRepository repository,
VectorStore vectorStore) {
// ...
this.ai = ai
.defaultTools(scheduler)
// ..
.build();
}
现在我们来尝试两步交互
http :8080/jlong/assistant question=="do you have any neurotic dogs?"
一旦确认有一只名叫 Prancer 的狗,就询问安排从纽约市地点接狗的时间。
http :8080/jlong/assistant question=="fantastic. when can i schedule an appointment to pickup Prancer from the New York City location?"
您应该会在控制台上看到方法被调用的确认,并且应该看到日期是三天以后。太好了。
我们已经开辟了大量的可能性!Spring AI 是一个简洁而强大的组件模型,Claude 是一个非常出色的聊天模型,我们已经集成了我们的数据和工具。然而,理想情况下,我们应该能够以统一的方式使用工具,而无需过度耦合到特定的编程模型。2025 年 11 月,Anthropic 发布了 Claude Desktop 的更新,其中包含一种名为模型上下文协议 (MCP) 的新网络协议。MCP 提供了一种便捷的方式,使模型能够从工具中获益,无论这些工具是用何种语言编写的。MCP 有两种风格:STDIO 和通过服务器发送事件 (SSE) 进行的 HTTP 流传输。
结果非常积极!自推出以来,我们目睹了新的 MCP 服务的寒武纪大爆发。有无数的 MCP 服务。有无数的 MCP 服务目录。现在,我们开始看到越来越多的新 MCP 服务目录!所有这些都对我们有利;每个 MCP 服务都是您可以教给模型的新技巧。有适用于 Spring Batch、Spring Cloud Config Server、Cloud Foundry、Heroku、AWS、Google Cloud、Azure、Microsoft Office、Github、Adobe 等的 MCP 服务。有 MCP 服务可以让您在 Blender3D 中渲染 3D 场景。有 MCP 服务可以依次连接任何数量的其他集成和服务,包括 Zapier 中的服务。
现在,我们要再添加一个。让我们将调度算法提取为 MCP 服务并重新使用它。访问 Spring Initializr 并选择 GraalVM Native Support、Web 和 Model Context Protocol Server。选择 Java 24(或更高版本)和 Apache Maven。将项目命名为 scheduler。点击 Generate,然后在使用您喜欢的 IDE 打开生成的 .zip 文件中的项目。
将 DogAdoptionScheduler 剪切并粘贴到新项目的底部。将以下定义添加到主类 (SchedulerApplication.java) 中。
@Bean
MethodToolCallbackProvider methodToolCallbackProvider(DogAdoptionScheduler scheduler) {
return MethodToolCallbackProvider
.builder()
.toolObjects(scheduler)
.build();
}
更改 application.properties 以确保新服务在不同的端口上启动。
# ...
server.port=8081
启动调度程序。返回 adoptions 模块,让我们重新配置它,使其指向这个新的基于远程 HTTP 的 MCP 服务。
删除代码中所有对 DogAdoptionScheduler 的引用。在配置中定义一个 McpSyncClient 类型的 bean。
@Bean
McpSyncClient mcpSyncClient() {
var mcp = McpClient
.sync(HttpClientSseClientTransport.builder("https://:8081").build()).build();
mcp.initialize();
return mcp;
}
现在,在构造函数中,指定一个工具回调,指向这个。
AdoptionsController(JdbcClient db,
McpSyncClient mcpSyncClient,
PromptChatMemoryAdvisor promptChatMemoryAdvisor,
ChatClient.Builder ai,
DogRepository repository,
VectorStore vectorStore) {
// ...
this.ai = ai
// ..
.defaultToolCallbacks(new SyncMcpToolCallbackProvider(mcpSyncClient))
// ..
.build();
}
重新启动进程,然后再次询问相同的问题,这次您应该会看到 MCP 服务最终会打印出日程安排的确认信息,并且建议的日期确实仍然是未来三天。
Claude Desktop 从一开始就支持使用 .json 配置文件配置 MCP 服务,为了方便互操作性,Spring AI 也支持这种配置格式。例如,这是 GitHub MCP 服务的 .json 配置:
{
"mcpServers": {
"github": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-e",
"GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "...."
}
}
}
}
注意:您需要在此处指定您自己的 GitHub 个人访问令牌。告诉 Spring AI 将该 MCP 定义包含为工具非常简单。例如,您只需将以下内容添加到 application.properties 文件中即可:
spring.ai.mcp.client.stdio.servers-configuration=classpath:/github-mcp.json
现在,您可以请求助手帮助您安排日程,然后让它将建议的日期写入 GitHub 中的文件,所有这些都无需任何干预。太棒了!
MCP 在 Claude Desktop 中首次亮相,在其推出时仅支持同一主机上的基于 STDIO 的服务。最近,情况发生了变化。Claude Desktop 刚刚增加了对 HTTP 远程 MCP 服务的支持,例如我们的 scheduler。您需要升级您的 Anthropic 账户,因为至少在撰写本文时,它仅在 Max 计划中可用。(我迫不及待地想要付费!)您可以将我们的调度服务重新用作您可以直接从 Claude Desktop 本身使用的工具。假设您已安装 Claude Desktop(撰写本文时它可在 macOS 和 Windows 上运行),您将按照以下步骤配置远程集成。
首先,您需要打开 Claude 的 Settings 屏幕。
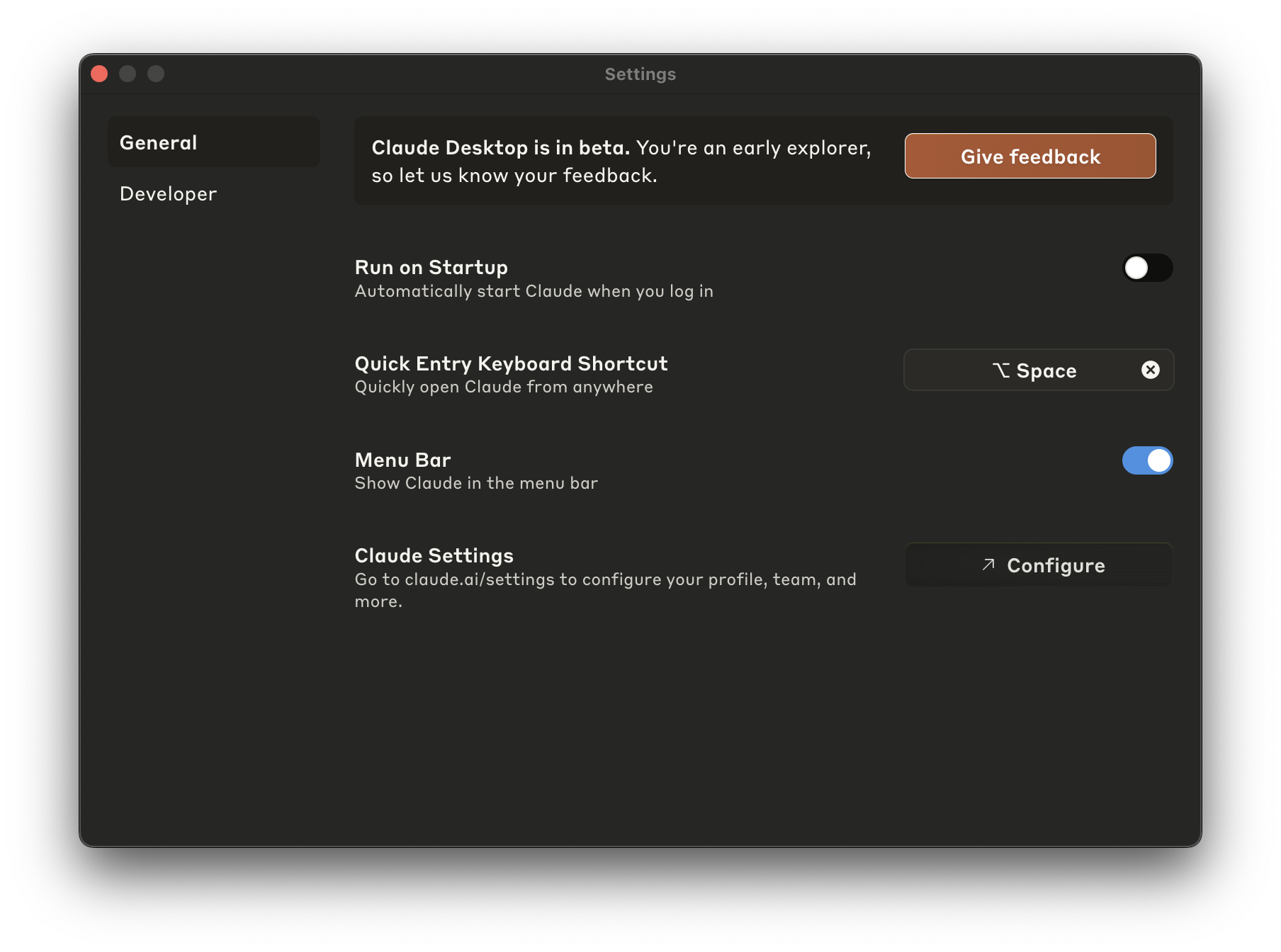
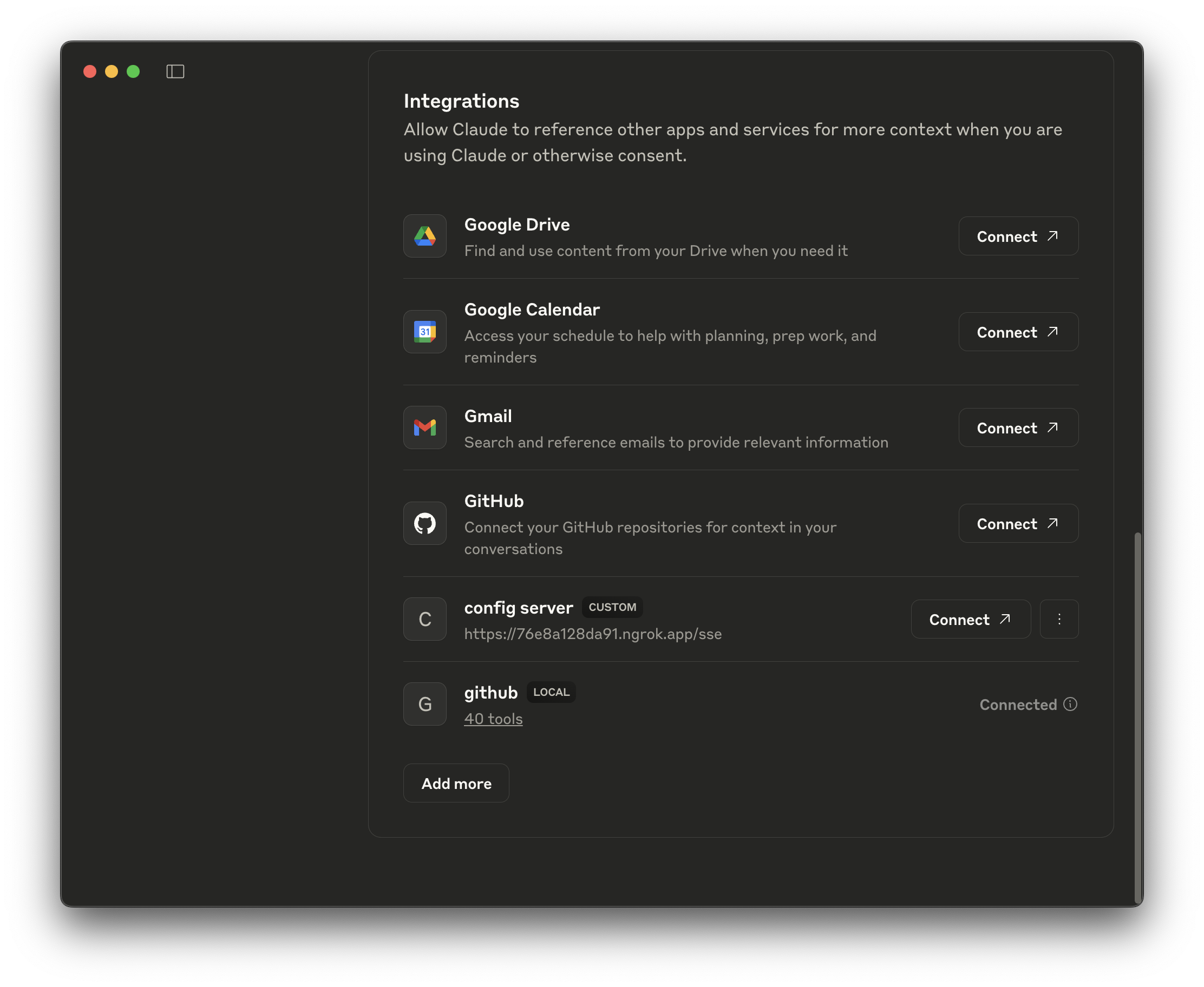
然后,打开 Settings 屏幕的 Integrations 部分。
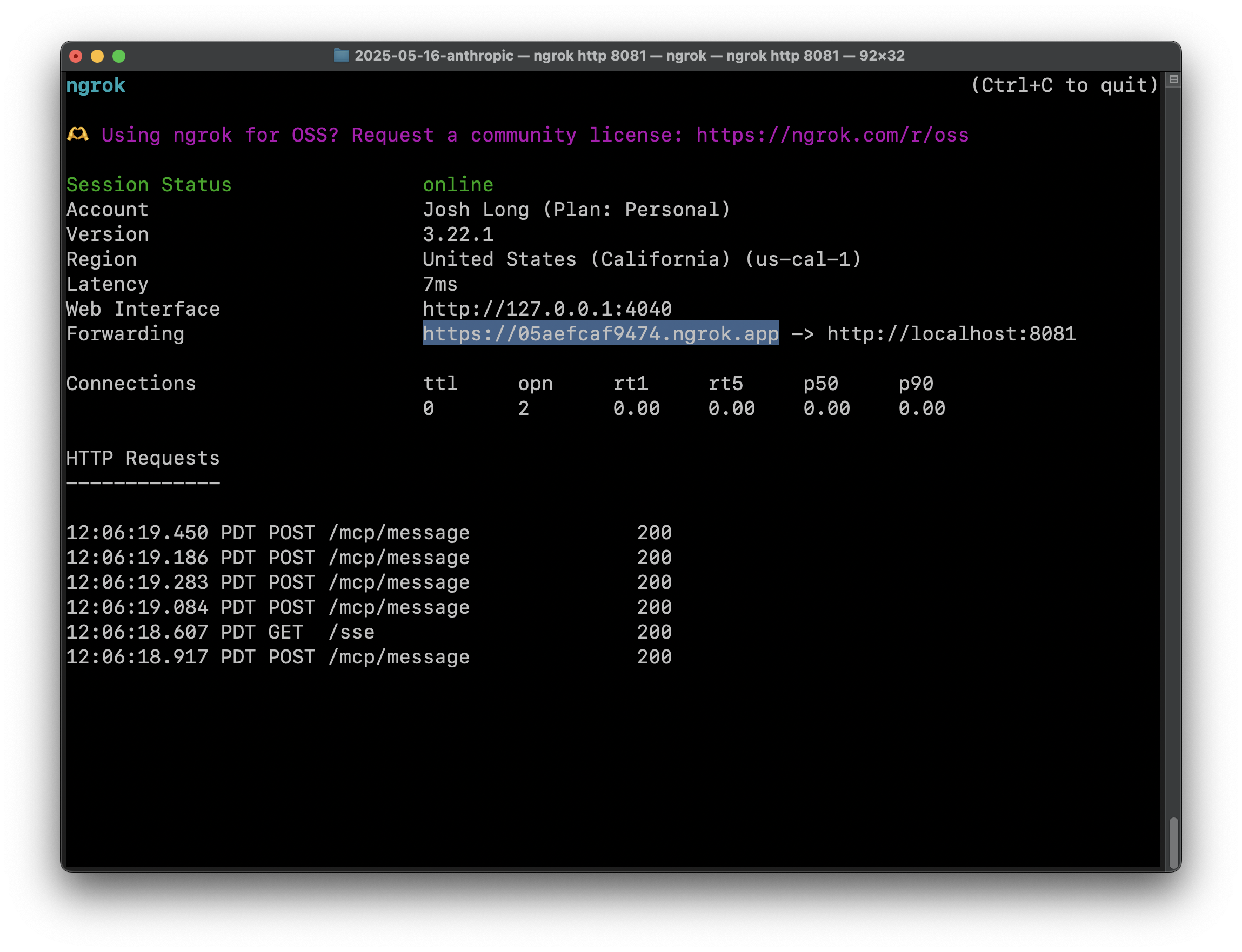
为了测试此服务,它需要有一个可公开访问的 URL。显然,您可以在很多地方运行您的应用程序(CloudFoundry、AWS、Google Cloud、Azure 等),但为了使开发更容易,我们推荐 ngrok?它将使您的本地服务在动态公共 URL 上可用。我们不得不付费升级才能让它停止显示插页式页面。如果我没记错的话,大约是 8 美元,这还不错。运行:
ngrok http 8081
这将建立一个通往在端口 8081 上运行的任何服务的隧道,允许您通过打印到控制台的动态 URL 访问它。
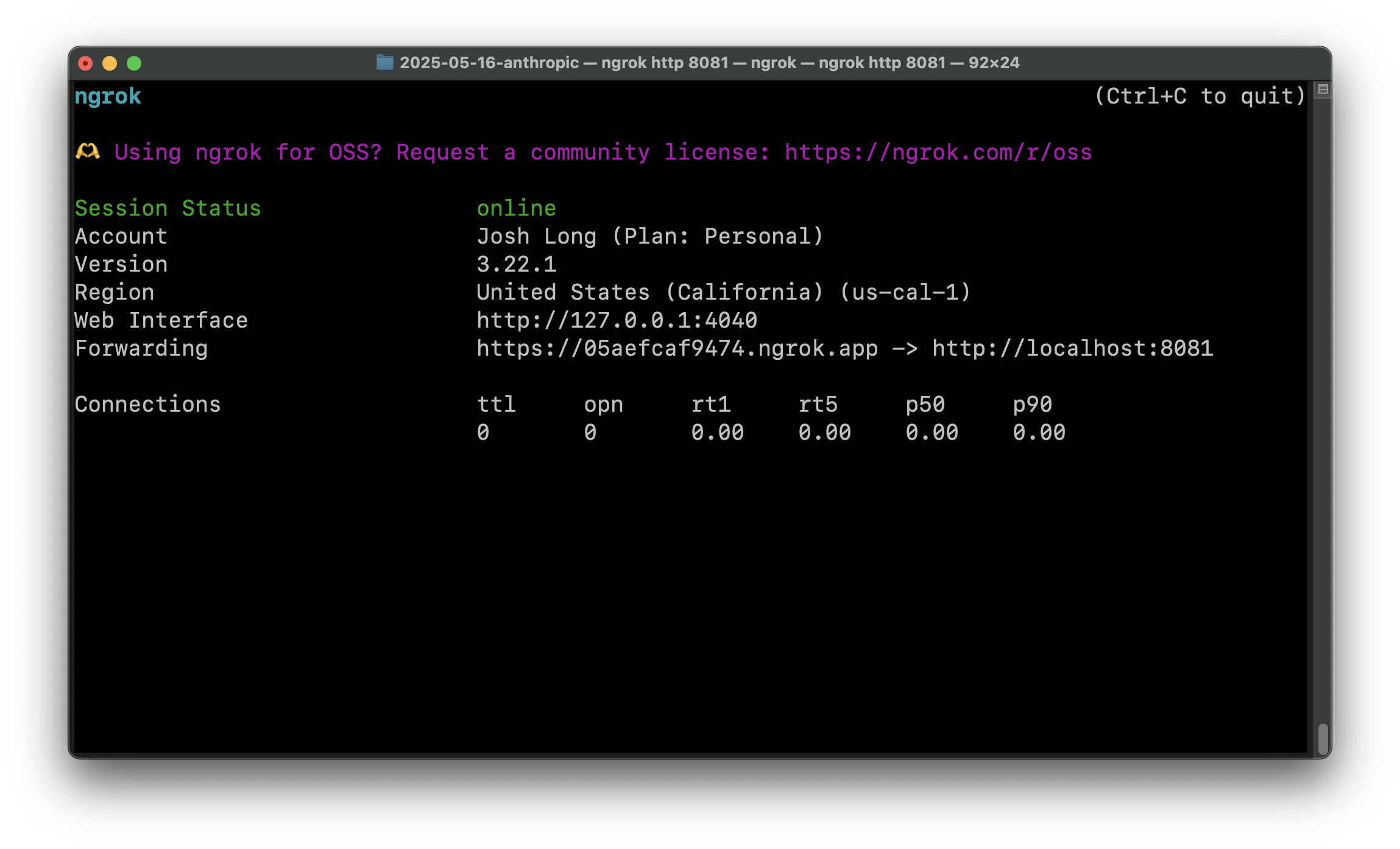
现在我们需要在 Settings 页面的 Integrations 部分中告诉 Claude Desktop 有关服务的信息。

在主屏幕上点击 Add,然后点击 Connect。您应该会在 ngrok 控制台中看到 Claude Desktop 和 scheduler 服务在端口 8081 之间连接的确认信息。
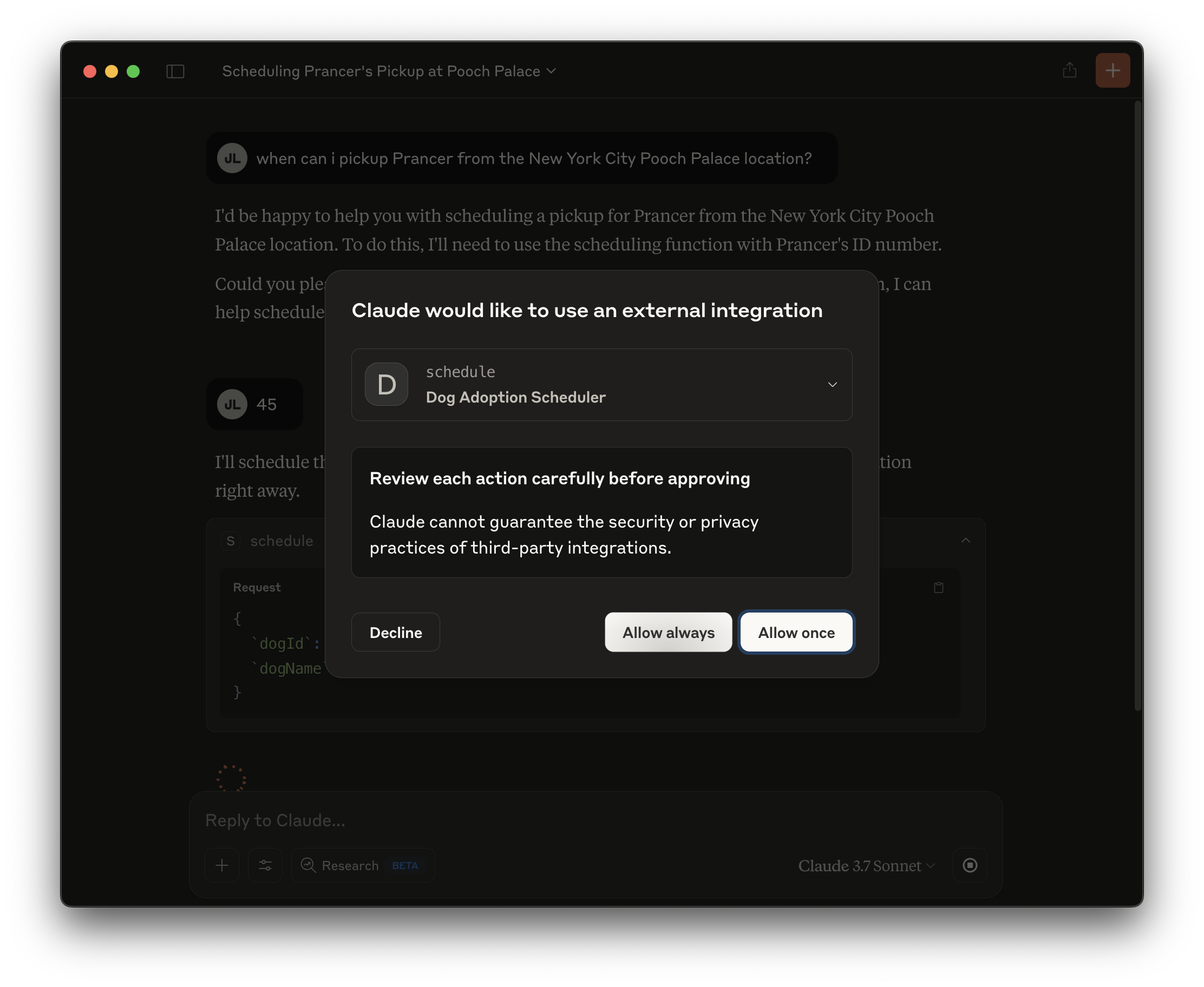
向 Claude Desktop 提出与上面相同的问题:“我什么时候可以预约从纽约市地点接 Prancer?”在我们的运行中,它还要求我们指定狗的 ID,我们指定了:45。它最终会提示您允许它调用您刚刚提供的工具。
服从它,然后它就开始工作了!
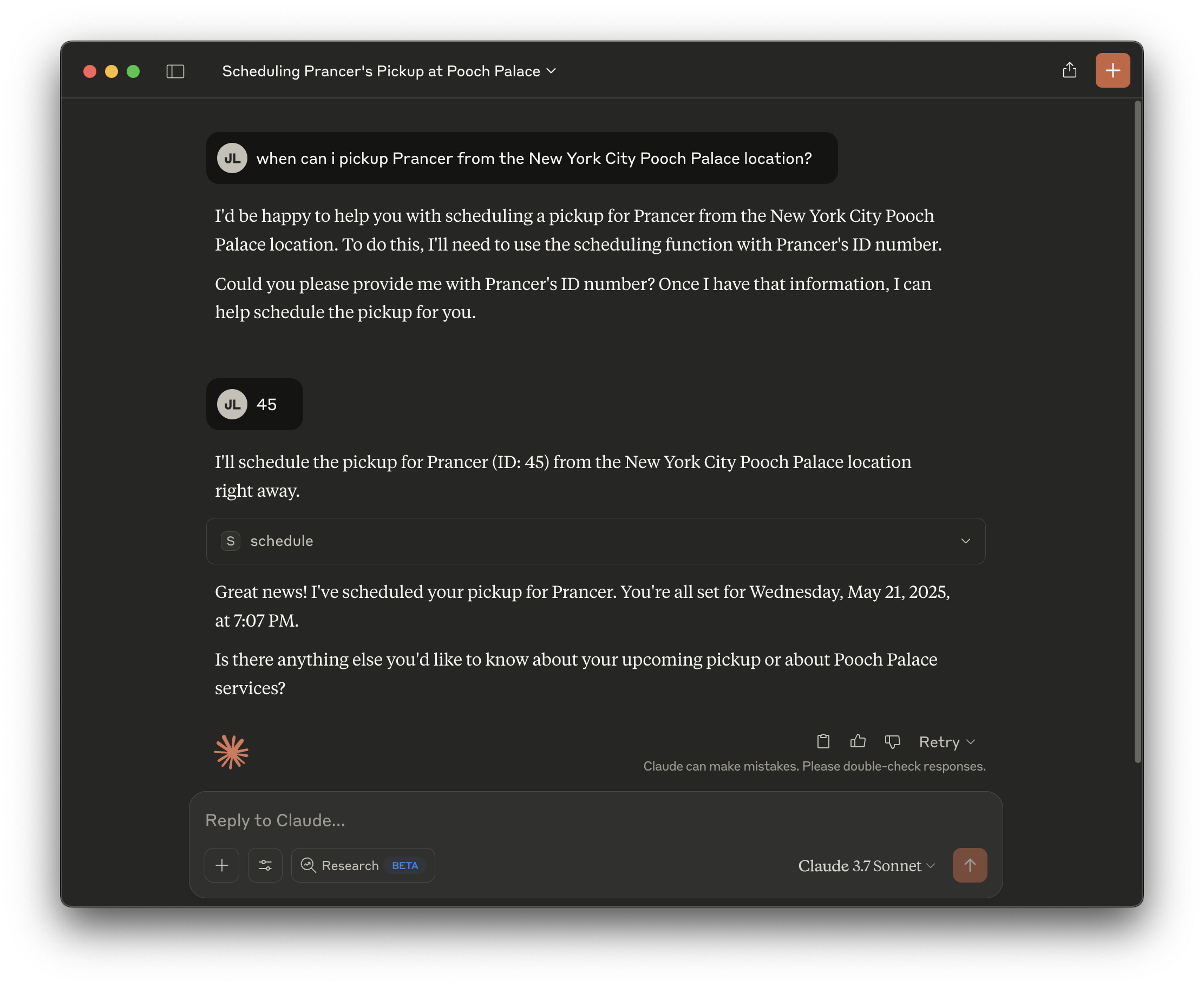
它应该会给你一个三天后的日期。太棒了!
现在,是时候将我们的目光转向生产了。
使用 Spring Security 锁定此 Web 应用程序非常简单。您还可以使用经过身份验证的 Principal#getName 作为会话 ID。数据库中存储的数据(如对话)怎么办?嗯,您有几个选择。许多数据库都支持作为被动功能的静态加密。
我们希望这段代码具有可扩展性。请记住,每次您向模型(或许多关系数据库)发出 HTTP 请求时,您都在执行阻塞 IO。IO 位于一个线程上,并且在该 IO 完成之前,该线程对系统中的任何其他需求都不可用。这是对一个完美线程的浪费!线程不应该只是空闲等待。Java 21 提供了虚拟线程,对于 IO 密集型服务来说,它可以显著提高可扩展性。这就是为什么您应该(几乎?)始终在 application.properties 文件中设置 spring.threads.virtual.enabled=true。
GraalVM 是一个由 Oracle 主导的 AOT 编译器,您可以通过 GraalVM 社区版开源项目或功能强大的(免费)Oracle GraalVM 发行版使用它。如果您正在使用 SDKMAN,安装其中任何一个都非常简单:sdk install java 24-graalce 或 sdk install java 24-graal。然后,确保使用这些 JDK 发行版之一,例如:sdk use java 24-graal,甚至将其设置为您的系统默认值 sdk default java 24-graalce。
请记住,我们用 GraalVM Native Support 配置了我们的两个 Spring AI 服务,这增加了一个构建插件,它将允许我们将此应用程序转换为特定于操作系统和架构的原生二进制文件。
./mvnw -DskipTests -Pnative native:compile
退后。你甚至可能有时间去喝杯咖啡……这在大多数机器上需要一分钟左右,但一旦完成,你就可以轻松运行二进制文件了。
./target/scheduler
该程序的启动时间将比在 JVM 上启动快得多。在我的机器上,它在不到十分之一秒的时间内启动。更好的是,您应该会发现应用程序占用的 RAM 比在 JVM 上占用的 RAM 少得多。当应用程序启动时,它会在日志顶部打印其进程标识符 (PID)。请注意,然后运行:
ps -o rss <PID>
该数字以千字节为单位,除以 1,000 即可得到兆字节数。无论您得到什么数字,我确信您会发现它远低于您在 JVM 上可能获得的数字。
你可能会说,这都很好,但我需要让它在我的云平台上运行,这意味着要把它变成一个 Docker 镜像。简单!
./mvnw -DskipTests -Pnative spring-boot:build-image
退后。这可能还需要一分钟。完成后,您会看到它打印出了已生成的 Docker 镜像的名称。您可以运行它,记得覆盖它在您的主机上引用的主机和端口。有趣的是:我们正在使用 macOS,令人惊讶的是,这个应用程序在模拟 Linux 的 macOS 虚拟机中运行时,启动速度甚至比直接在 macOS 上运行还要快——而且从一开始就如此!太棒了!
这个应用程序真是太棒了;我敢打赌它会像 Prancer 一样很快成为头条新闻。当这种情况发生时,您最好密切关注您的系统资源,以及最重要的——令牌计数。所有对 LLM 的请求都有成本——至少是复杂性成本,如果不是美元和美分的话。正如我们之前探讨的,Spring Boot 的可观察性在这里是理想的选择。
您刚刚构建了一个由 Claude、PostgresSQL 和 Spring AI 提供支持的生产级 AI 应用程序。我们希望您今天就能在 Spring Initializr 上开始使用。