
超越自我
VMware 提供培训和认证,助您加速进步。
了解更多#引言#
开发流处理应用时,一个常见的问题是:“每秒可以处理多少事件?”。这篇博文的主要目的是回答这个问题,同时避免落入基准测试与“基准营销”这一经典的基准测试难题。消息中间件供应商提供的“原生”基准测试应用通常关注原始数据传输速度,不涉及消息数据的序列化或反序列化,也没有任何数据处理。在本系列的第一部分,我们将遵循这种方法。
我们的测试在生产者和消费者同时运行的场景下,使用了 Spring XD 中的直连绑定(内存中)和 Apache KafkaⓇ 传输。这种测试场景模拟了实时流处理,而不是仅有生产者或仅有消费者的测试套件。直连绑定的测试场景使用单个容器,而 Kafka 传输则使用多个容器。每次测试都改变了事件(消息)的大小,结果显示了每秒消耗的总消息数和总 MB 数。对于 Kafka 传输测试,我们使用了 Kafka 提供的性能工具,为配置的基础设施提供了基准测试。 ##什么是 Spring XD?## Spring XD 是一个统一、分布式且可扩展的系统,用于数据摄取、实时分析、批处理和数据导出。该项目的目标是简化大数据或企业流处理/批处理应用的开发。更多关于 XD 的信息可在此处找到:这里。 ##架构## 所有测试均使用 RackSpace OnMetal 服务器运行,以保证所有服务的网络速度,并为基于 Kafka 的测试提供适当的磁盘写入速度。有关此选择的更多详细信息请见下文。所用服务器的规格如下: ###服务器实例类型###
###网络:### 所有测试都在 10 千兆网络上运行 Spring XD,平均速度为 1117 MB/s 或 8.936 Gbps。我们使用 iperf 来确定网络性能,客户端使用以下命令: iperf -c ,服务器使用 iperf -s 命令。###磁盘:### 所有需要高性能磁盘写入的测试都在 OnMetal IO 数据盘上实现。这些设备的平均磁盘写入速度约为 ~934 MB/s。用于验证磁盘写入速度的命令是 dd if=/dev/zero of=/data1/largefile bs=1M count=10000 conv=fdatasync。dd 命令中的 fdatasync 要求在退出前进行完整的“同步”,从而验证数据是否完全写入磁盘而非缓存。 ##工具## 用于测试传输的两个主要工具是位于 github spring-xd-modules 项目中的 load-generator 源模块和 throughput 汇模块。load-generator 源模块在内存中生成数据,并且可以配置为发送特定数量的特定大小的消息。throughput 模块是一个汇,它计算接收到的消息并定期将测得的吞吐量报告到日志中。
#传输测试# ##直连绑定传输## 为了消除网络延迟,有时最好让同址的、连续的模块直接通信,而不是使用配置的远程传输。Spring XD 默认只在生产者和消费者(管道两侧绑定的模块)的每一“对”都保证位于同一 JVM 中的情况下创建直连绑定。这个基准测试的目的是展示使用直连绑定的单个 XD 容器的消息吞吐量。在这种场景下,我们在单个容器中发送并消耗了 5 亿条消息。以下流定义用于捕获 1000 字节消息测试的结果:stream create directBindingTest --definition "load-generator --messageCount=500000000 --messageSize=1000 | throughput" stream deploy directBindingTest --properties module.*.count=0 下图显示了消息大小为 100、1000、10000 和 100000 字节时的每秒消息数/MB 数:###每秒消息数### 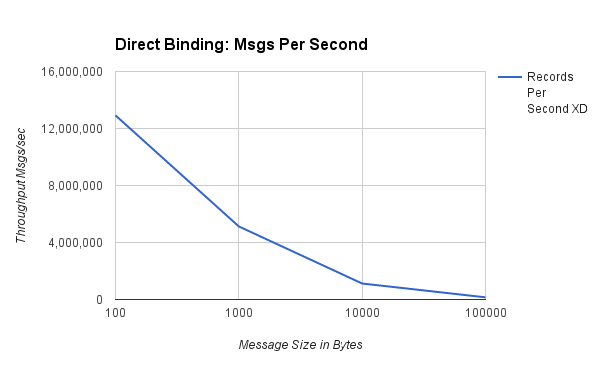 ###每秒兆字节数###
###每秒兆字节数### 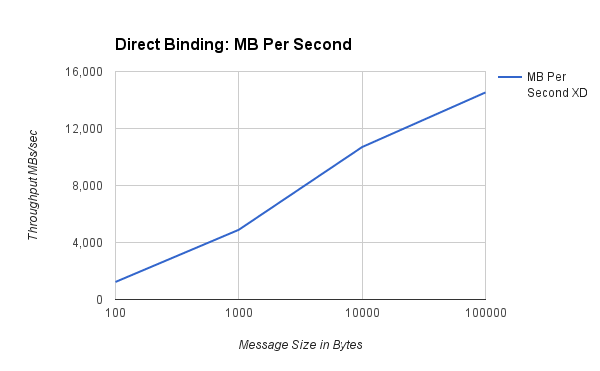
| 消息大小 | Spring XD 每秒消息数 | Spring XD 每秒 MB 数 |
|---|---|---|
| 100 | 12,919,560 | 1,232 |
| 1,000 | 5,126,920 | 4,893 |
| 10,000 | 1,121,921 | 10,699 |
| 100,000 | 152,364 | 14,530 |
图表显示,随着消息大小增加,速率降低,但总体数据吞吐量增加。对于 100 到 1000 字节范围内的典型大小负载,我们能够使用单个线程每秒推送 500 万到 1200 万个事件。在此规模下进行小操作(例如访问哈希表中的数据)的成本意味着任何数据处理都会显著降低速率。
##Kafka 传输## ###测试拓扑###
对于 Kafka 测试,我们创建了以下拓扑
在三台 OnMetal I/O 实例上设置了一个三代理的 Kafka 集群。每个 Kafka 实例有两块 SSD,没有配置 RAID。一个 Zookeeper 实例在 Kafka 代理和 XD 之间共享,并部署在一台 Compute v1 Rackspace 实例上。XD 集群部署在 2 台 OnMetal Compute 实例上。RS(RackSpace)实例一托管了一个 XD-Admin、一个 HSQLDB 和一个 xd-container。RS(RackSpace)实例二托管了一个 xd-container。
####实例类型选择#### 实例类型的选择基于处理器速度、磁盘写入速度以及能够处理数据量的网络。最初的测试计划在 EC2 上进行,但我们发现临时磁盘的写入速度太慢(约 ~75 MB/s),无法让 Kafka 达到峰值性能。我们计划在新发布的 D2 实例类型上重新运行测试。我们决定使用 Rackspace OnMetal I/O 来利用高性能 SSD(约 ~934 MB/s)。####测试#### 此基准测试的目的是展示源(生产者)和汇(消费者)使用 Kafka 作为传输,在不同机器上的两个不同 XD 容器中运行时的消息吞吐量。此基准测试的目标是获取 Kafka 自身测试工具的原生统计数据,并将其与 Spring XD 在同一组测试中的结果进行比较。这种比较很重要,因为 XD 不使用标准的 Kafka Consumer API,而是使用 Spring Integration Kafka 适配器,后者添加了额外的功能,例如控制从哪个偏移量消费以及从主题的哪个分区消费。在每种情况下,都会创建一个具有六个分区和三个副本的主题。生产者将放置在 RS 实例一上,消费者将放置在 RS 实例二上。所有这些测试的负载都只使用字节数组数据。因此,对于这些测试,Spring XD 将 Kafka 传输模式设置为 raw。Raw 模式表示 Spring XD 不会嵌入头部,并将序列化的处理留给用户。
使用与 Apache Kafka 基准测试:每秒写入 200 万次 中演示的相同方式使用 Kafka 的性能工具,我们希望确定 Kafka 集群的基础速度。在下面的示例中,以下生产者/消费者命令用于 1000 字节消息测试的这些结果
生产者: ./bin/kafka-topics.sh --zookeeper ./bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance $1 300000000 1000 -1 acks=1 bootstrap.servers= 消费者: ./bin/kafka-run-class.sh ./bin/kafka-consumer-perf-test.sh --zookeeper
Spring XD 1.2 使用了新的 Spring Integration Kafka 适配器,它提供了比标准 Kafka 客户端库更丰富的功能集。XD 的配置是开箱即用的,除了我们在 servers.yml 中设置了以下配置以匹配原生测试中使用的配置:
要了解更多关于这些配置的信息,请查阅我们的文档:这里。
以下流用于 1000 字节消息测试的结果: stream create myTest --definition "load-generator --messageCount=300000000 --messageSize=1000 | throughput" stream deploy myTest ####吞吐量#### #####每秒消息数##### 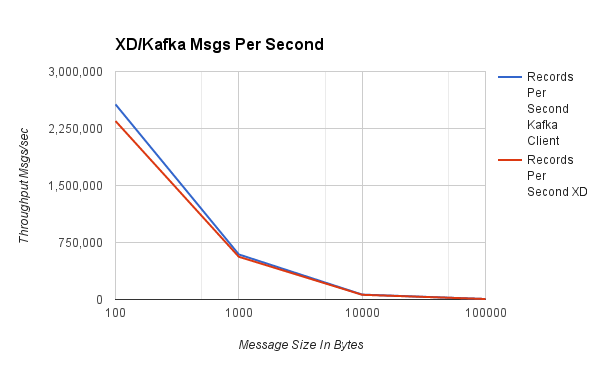
| 消息大小 | Kafka 客户端每秒消息数 | Spring XD 每秒消息数 |
|---|---|---|
| 100 | 2,567,657 | 2,348,289 |
| 1,000 | 592,881 | 562,113 |
| 10,000 | 64,806 | 61,985 |
| 100,000 | 6,505 | 6,341 |
| #####每秒兆字节数##### |
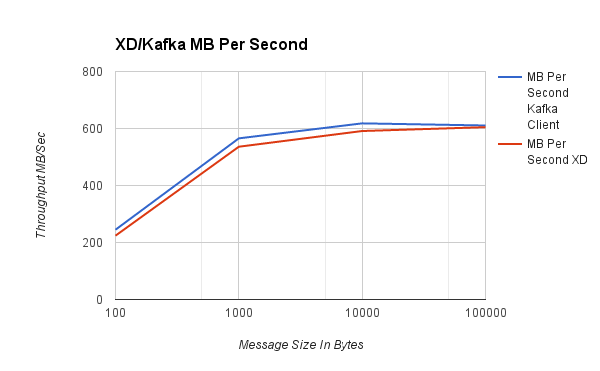
| 消息大小 | Kafka 客户端每秒 MB 数 | Spring XD 每秒 MB 数 |
|---|---|---|
| 100 | 245 | 224 |
| 1,000 | 565 | 536 |
| 10,000 | 618 | 591 |
| 100,000 | 611 | 605 |
与直连绑定基准测试类似,图表显示随着消息大小增加,速率降低,但总体数据吞吐量增加。对于 100 到 1000 字节范围内的典型大小负载,我们能够使用单个线程每秒推送 60 万到约 200 万个事件。值得注意的是,Spring XD 的基准测试(基于功能更丰富的消费者库)与 Kafka 原生客户端 API 的基准测试结果相差不超过 8%。另请注意,在 1000 到 10000 字节的消息大小之间,单个生产者可以达到 10Gb 网络容量的一半左右。在未来的测试中,我们将展示多个生产者和消费者的基准测试,以展示 XD 如何扩展以及批量大小等其他调优参数如何影响性能。
#结论# 上述基准测试表明,Spring XD 可以满足高性能流处理的使用案例需求。它们还表明,与原生 Kafka 高级消费者库相比,使用 Spring Integration Kafka (SIK) 客户端库的 Spring XD 引入的开销非常小,同时提供了额外的功能,例如控制偏移量和分区。因此,您可以利用 Spring XD 编程模型以及 SIK 消费者 API 中的功能,而对性能的影响最小。
#后续步骤# 虽然有些使用案例主要侧重于数据直通,但大多数使用案例会涉及对负载进行一些处理。此外,我们仅使用了单个处理线程。在未来的博文中,我们将展示 XD 如何通过更多容器实例进行扩展,使用常用库对对象进行反序列化/序列化时如何影响消息速率,以及多线程和响应式编程如何帮助提高每个 JVM 进程的速率。敬请关注!
编者注:©2015 Pivotal Software, Inc. 保留所有权利。Apache 和 Apache Kafka 是 Apache Software Foundation 在美国和/或其他国家的注册商标或商标。