
领先一步
VMware 提供培训和认证,助您加速进步。
了解更多这篇博文由我们杰出的贡献者Thomas Vitale 联合撰写。
OpenAI 提供了专门的 `speech-to-text` 和 `text-to-speech` 转换模型,以其性能和成本效益而闻名。Spring AI 通过语音转文本和文本转语音 (TTS) 集成了这些功能。
新的 音频生成 功能 (gpt-4o-audio-preview) 更进一步,实现了混合输入和输出模式。音频输入可以包含比纯文本更丰富的数据。音频可以传达细微的语气和语调等信息,并且结合音频输出,它能够实现异步的 语音转语音 交互。此外,这种新的多模态能力为结构化数据提取等创新应用开辟了可能性。开发者不仅可以从纯文本中提取结构化信息,还可以从图像和音频中提取,无缝构建复杂的结构化对象。
Spring AI 的 多模态消息 API 简化了将多模态能力与各种 AI 模型集成的工作。
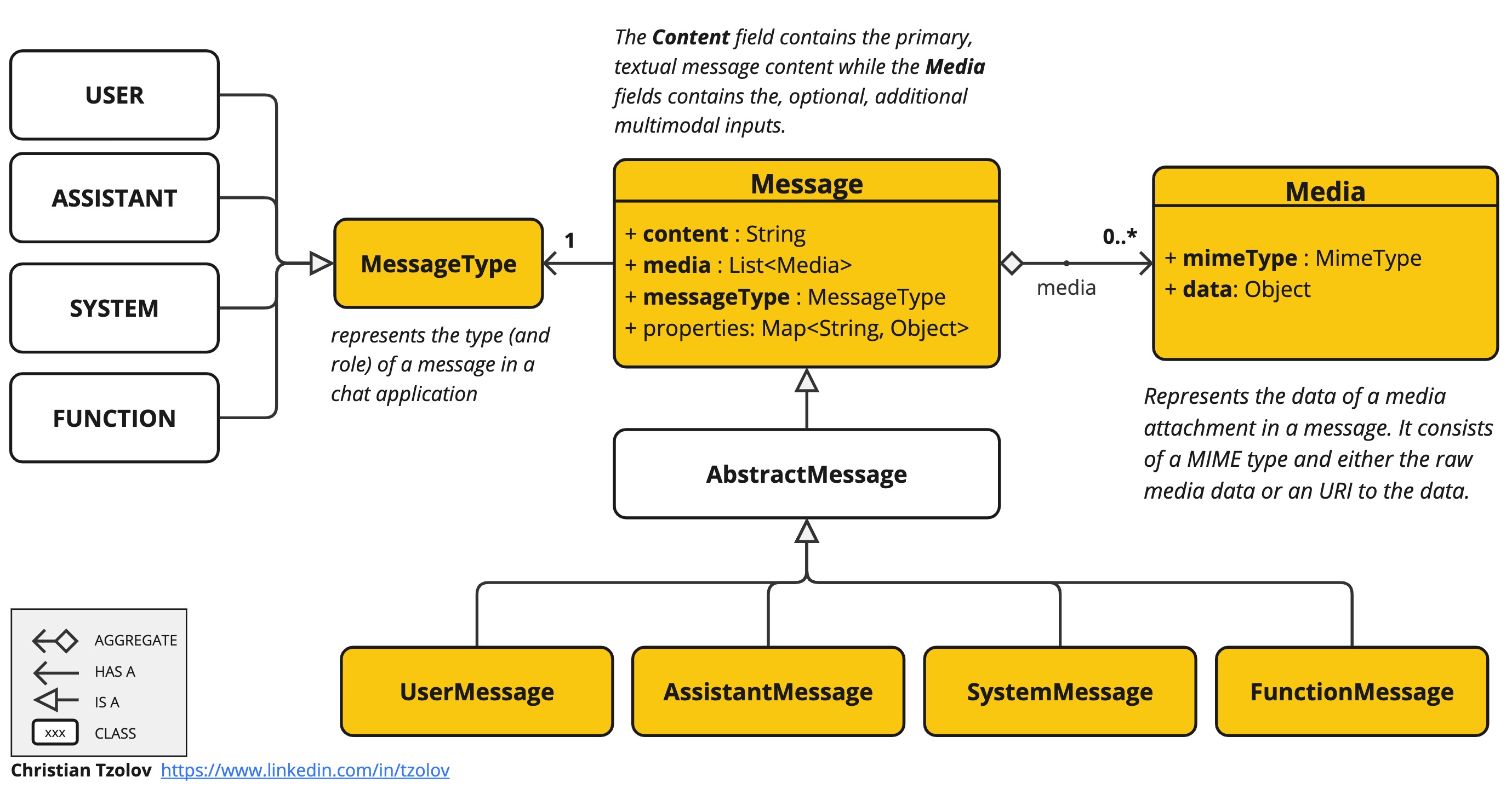
现在,它完全支持 OpenAI 的 音频输入 和 音频输出 模式,这在很大程度上得益于社区成员 Thomas Vitale 对该功能开发的贡献。
请遵循 Spring AI-OpenAI 集成文档来准备您的环境。
OpenAI 的 用户消息 API 接受消息中的 base64 编码音频文件,使用 Media 类型。支持的格式包括 audio/mp3 和 audio/wav。
示例:向输入提示中添加音频
// Prepare the audio resource
var audioResource = new ClassPathResource("speech1.mp3");
// Create a user message with audio and send it to the chat model
String response = chatClient.prompt()
.user(u -> u.text("What is this recording about?")
.media(MimeTypeUtils.parseMimeType("audio/mp3"), audioResource))
.options(OpenAiChatOptions.builder()
.withModel(OpenAiApi.ChatModel.GPT_4_O_AUDIO_PREVIEW).build())
.call()
.content();
OpenAI 的 助手消息 API 可以使用 Media 类型返回 base64 编码的音频文件。
示例:生成音频输出
// Generate an audio response
ChatResponse response = chatClient
.prompt("Tell me a joke about the Spring Framework")
.options(OpenAiChatOptions.builder()
.withModel(OpenAiApi.ChatModel.GPT_4_O_AUDIO_PREVIEW)
.withOutputModalities(List.of("text", "audio"))
.withOutputAudio(new AudioParameters(Voice.ALLOY, AudioResponseFormat.WAV))
.build())
.call()
.chatResponse();
// Access the audio transcript
String audioTranscript = response.getResult().getOutput().getContent();
// Retrieve the generated audio
byte[] generatedAudio = response.getResult().getOutput().getMedia().get(0).getDataAsByteArray();
要生成音频输出,请在 OpenAiChatOptions 中指定音频模式。使用 AudioParameters 类来自定义语音和音频格式。
此示例演示了如何使用支持输入和输出音频的 Spring AI 构建一个交互式聊天机器人。它展示了 AI 如何通过自然的音频回复来增强用户交互。
添加 Spring AI OpenAI 启动器
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
在 application.properties 中配置 API 密钥、模型名称和输出音频模式
spring.main.web-application-type=none
spring.ai.openai.api-key=${OPENAI_API_KEY}
spring.ai.openai.chat.options.model=gpt-4o-audio-preview
spring.ai.openai.chat.options.output-modalities=text,audio
spring.ai.openai.chat.options.output-audio.voice=ALLOY
spring.ai.openai.chat.options.output-audio.format=WAV
下面详细介绍的语音聊天机器人的 Java 实现,使用音频输入和输出来创建一个会话式 AI 助手。它利用 Spring AI 与 OpenAI 模型的集成,实现了与用户的无缝交互。
VoiceAssistantApplication
VoiceAssistantApplication 作为主应用程序。
CommandLineRunner bean 初始化聊天机器人
ChatClient 使用 systemPrompt 进行上下文理解,并使用内存中的聊天记录进行对话历史记录。Audio 工具用于录制用户的语音输入,并播放 AI 生成的音频响应。聊天循环: 在循环中
audio.startRecording() 和 audio.stopRecording() 方法处理录制过程,暂停以等待用户输入。chatClient.prompt() 将用户消息发送到 AI 模型。音频数据封装在 Media 对象中。Audio.play() 方法播放为音频。有关实现,请参阅以下代码片段
@Bean
public CommandLineRunner chatBot(ChatClient.Builder chatClientBuilder,
@Value("${chatbot.prompt:classpath:/marvin.paranoid.android.txt}") Resource systemPrompt) {
return args -> {
var chatClient = chatClientBuilder.defaultSystem(systemPrompt)
.defaultAdvisors(new MessageChatMemoryAdvisor(new InMemoryChatMemory()))
.build();
try (Scanner scanner = new Scanner(System.in)) {
Audio audio = new Audio();
while (true) {
audio.startRecording();
System.out.print("Recording your question ... press <Enter> to stop! ");
scanner.nextLine();
audio.stopRecording();
System.out.print("PROCESSING ... ");
AssistantMessage response = chatClient.prompt()
.messages(new UserMessage("Please answer the questions in the audio input",
new Media(MediaType.parseMediaType("audio/wav"),
new ByteArrayResource(audio.getLastRecording()))))
.call()
.chatResponse()
.getResult()
.getOutput();
System.out.println("ASSISTANT: " + response.getContent());
Audio.play(response.getMedia().get(0).getDataAsByteArray());
}
}
};
}
用于捕获和播放音频的 Audio 工具是一个利用纯 Java Sound API 的单一类。
▗▄▄▖▗▄▄▖ ▗▄▄▖ ▗▄▄▄▖▗▖ ▗▖ ▗▄▄▖ ▗▄▖ ▗▄▄▄▖
▐▌ ▐▌ ▐▌▐▌ ▐▌ █ ▐▛▚▖▐▌▐▌ ▐▌ ▐▌ █
▝▀▚▖▐▛▀▘ ▐▛▀▚▖ █ ▐▌ ▝▜▌▐▌▝▜▌ ▐▛▀▜▌ █
▗▄▄▞▘▐▌ ▐▌ ▐▌▗▄█▄▖▐▌ ▐▌▝▚▄▞▘ ▐▌ ▐▌▗▄█▄▖
▗▄▄▖ ▗▄▖ ▗▄▄▖ ▗▄▖ ▗▖ ▗▖ ▗▄▖ ▗▄▄▄▖▗▄▄▄ ▗▄▖ ▗▖ ▗▖▗▄▄▄ ▗▄▄▖ ▗▄▖ ▗▄▄▄▖▗▄▄▄
▐▌ ▐▌▐▌ ▐▌▐▌ ▐▌▐▌ ▐▌▐▛▚▖▐▌▐▌ ▐▌ █ ▐▌ █ ▐▌ ▐▌▐▛▚▖▐▌▐▌ █▐▌ ▐▌▐▌ ▐▌ █ ▐▌ █
▐▛▀▘ ▐▛▀▜▌▐▛▀▚▖▐▛▀▜▌▐▌ ▝▜▌▐▌ ▐▌ █ ▐▌ █ ▐▛▀▜▌▐▌ ▝▜▌▐▌ █▐▛▀▚▖▐▌ ▐▌ █ ▐▌ █
▐▌ ▐▌ ▐▌▐▌ ▐▌▐▌ ▐▌▐▌ ▐▌▝▚▄▞▘▗▄█▄▖▐▙▄▄▀ ▐▌ ▐▌▐▌ ▐▌▐▙▄▄▀▐▌ ▐▌▝▚▄▞▘▗▄█▄▖▐▙▄▄▀
2024-12-01T11:00:11.274+01:00 INFO 31297 --- [voice-assistant-chatbot] [ main] s.a.d.a.m.VoiceAssistantApplication : Started VoiceAssistantApplication in 0.827 seconds (process running for 1.054)
Recording your question ... press <Enter> to stop!
完整的演示可在 GitHub 上找到:voice-assistant-chatbot
modalities = ["text", "audio"]。gpt-4o-audio-preview 模型为动态音频交互解锁了新的可能性,使开发者能够构建丰富的、由 AI 驱动的音频应用程序。
免责声明:API 功能和特性可能会发生变化。请参考最新的 OpenAI 和 Spring AI 文档以获取更新。