
领先一步
VMware 提供培训和认证,助您快速提升。
了解更多Spring AI 现在支持 NVIDIA 的大型语言模型 API,提供了与各种模型的集成。通过利用 NVIDIA 的与 OpenAI 兼容的 API,Spring AI 使开发者能够通过熟悉的Spring AI API 使用 NVIDIA 的 LLM。
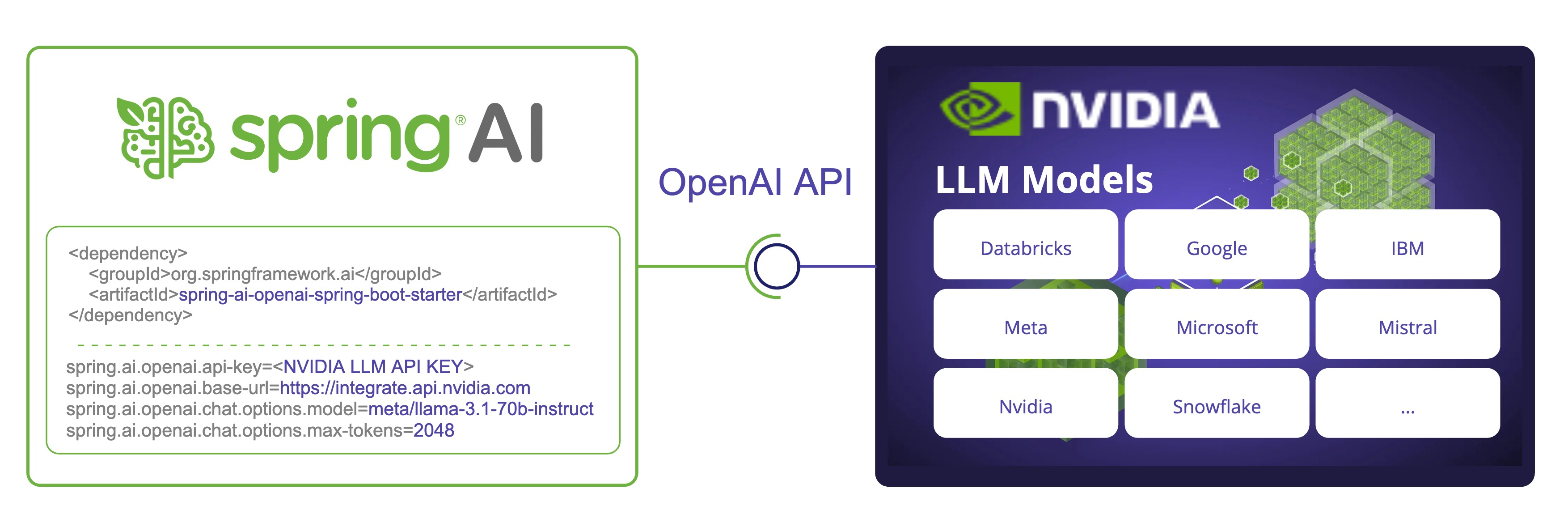
我们将探讨如何配置和使用 Spring AI OpenAI 聊天客户端来连接 NVIDIA LLM API。
meta/llama-3.1-70b-instruct。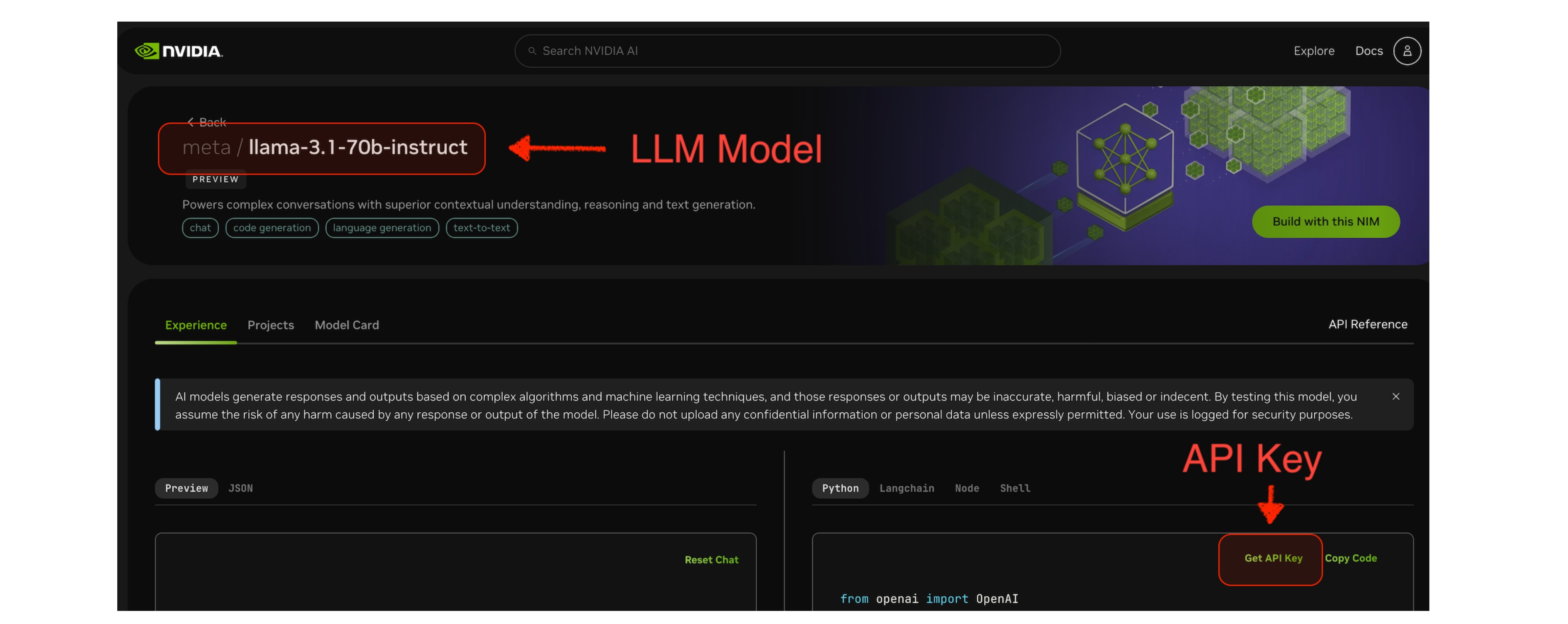
要开始使用,请将 Spring AI OpenAI Starter 添加到您的项目中。对于 Maven,将其添加到 pom.xml 中:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
对于 Gradle,将其添加到 build.gradle 中:
gradleCopydependencies {
implementation 'org.springframework.ai:spring-ai-openai-spring-boot-starter'
}
确保您已添加 Spring Milestone 和 Snapshot 仓库并添加 Spring AI BOM。
要将 NVIDIA LLM API 与 Spring AI 一起使用,我们需要配置 OpenAI 客户端指向 NVIDIA LLM API 端点并使用 NVIDIA 特定的模型。
将以下环境变量添加到您的项目中:
export SPRING_AI_OPENAI_API_KEY=<NVIDIA_API_KEY>
export SPRING_AI_OPENAI_BASE_URL=https://integrate.api.nvidia.com
export SPRING_AI_OPENAI_CHAT_OPTIONS_MODEL=meta/llama-3.1-70b-instruct
export SPRING_AI_OPENAI_EMBEDDING_ENABLED=false
export SPRING_AI_OPENAI_CHAT_OPTIONS_MAX_TOKENS=2048
或者,您可以将这些添加到 application.properties 文件中:
spring.ai.openai.api-key=<NVIDIA_API_KEY>
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.options.model=meta/llama-3.1-70b-instruct
# The NVIDIA LLM API doesn't support embeddings.
spring.ai.openai.embedding.enabled=false
# The NVIDIA LLM API requires this parameter to be set explicitly or error will be thrown.
spring.ai.openai.chat.options.max-tokens=2048
要点
api-key 设置为您的 NVIDIA API 密钥。base-url 设置为 NVIDIA 的 LLM API 端点:https://integrate.api.nvidia.commodel 设置为 NVIDIA LLM API 上可用的模型之一。max-tokens,否则会抛出服务器错误。embedding.enabled=false。查看参考文档以获取完整的配置属性列表。
现在我们已经配置了 Spring AI 使用 NVIDIA LLM API,让我们看一个如何在应用程序中使用它的简单示例。
@RestController
public class ChatController {
private final ChatClient chatClient;
@Autowired
public ChatController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@GetMapping("/ai/generate")
public String generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return chatClient.prompt().user(message).call().content();
}
@GetMapping("/ai/generateStream")
public Flux<String> generateStream(
@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return chatClient.prompt().user(message).stream().content();
}
}
在 ChatController.java 示例中,我们创建了一个带有两个端点的简单 REST 控制器:
/ai/generate: 生成对给定提示的单个响应。/ai/generateStream: 流式传输响应,这对于较长的输出或实时交互非常有用。选择支持工具/函数的模型时,NVIDIA LLM API 端点支持工具/函数调用。
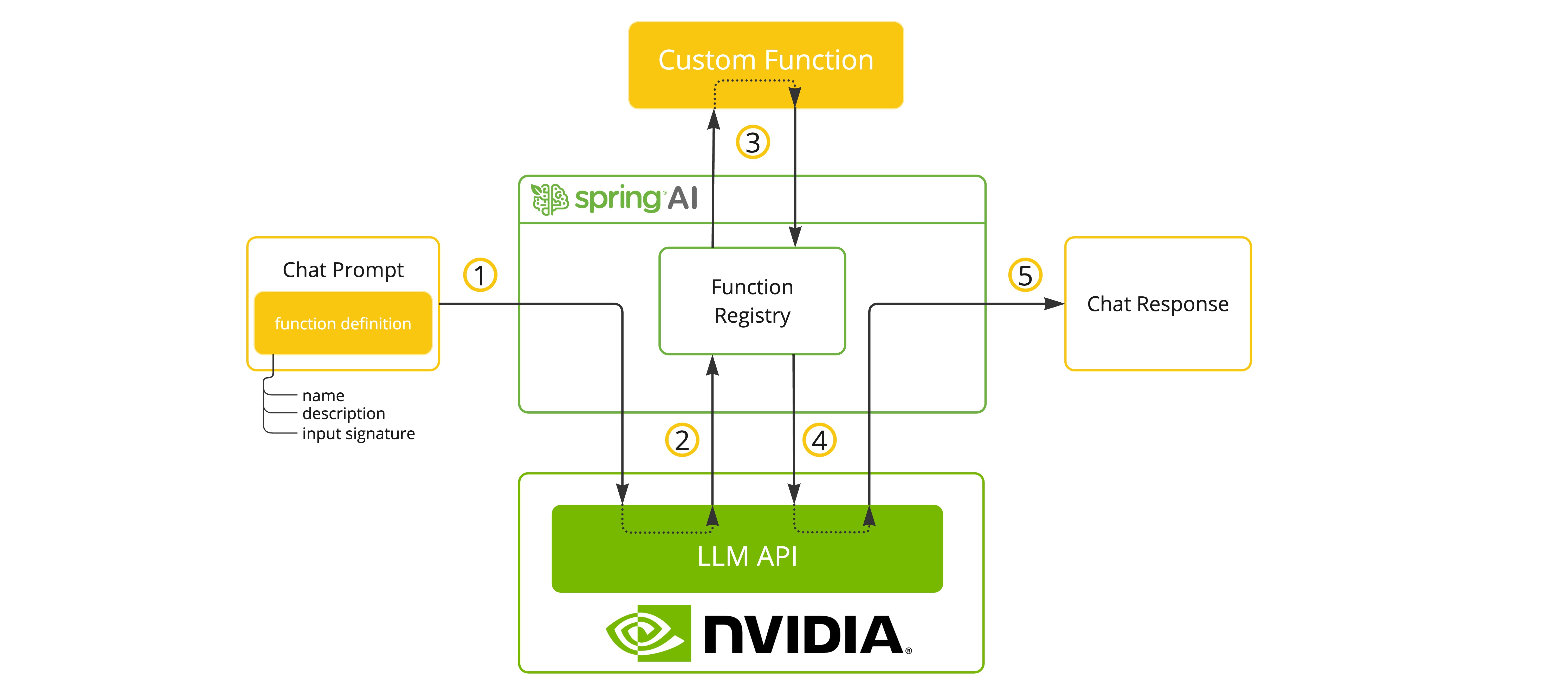
您可以使用 ChatModel 注册自定义 Java 函数,并让提供的 LLM 模型智能地选择输出一个 JSON 对象,其中包含调用一个或多个已注册函数的参数。这是将 LLM 能力与外部工具和 API 连接起来的强大技术。
查找更多关于 SpringAI/OpenAI 函数调用支持的信息。
以下是使用 Spring AI 进行工具/函数调用的简单示例:
@SpringBootApplication
public class NvidiaLlmApplication {
public static void main(String[] args) {
SpringApplication.run(NvidiaLlmApplication.class, args);
}
@Bean
CommandLineRunner runner(ChatClient.Builder chatClientBuilder) {
return args -> {
var chatClient = chatClientBuilder.build();
var response = chatClient.prompt()
.user("What is the weather in Amsterdam and Paris?")
.functions("weatherFunction") // reference by bean name.
.call()
.content();
System.out.println(response);
};
}
@Bean
@Description("Get the weather in location")
public Function<WeatherRequest, WeatherResponse> weatherFunction() {
return new MockWeatherService();
}
public static class MockWeatherService implements Function<WeatherRequest, WeatherResponse> {
public record WeatherRequest(String location, String unit) {}
public record WeatherResponse(double temp, String unit) {}
@Override
public WeatherResponse apply(WeatherRequest request) {
double temperature = request.location().contains("Amsterdam") ? 20 : 25;
return new WeatherResponse(temperature, request.unit);
}
}
}
在 NvidiaLlmApplication.java 示例中,当模型需要天气信息时,它会自动调用 weatherFunction bean,然后该 bean 可以获取实时天气数据。期望的响应如下:
阿姆斯特丹目前的天气是 20 摄氏度,巴黎目前的天气是 25 摄氏度。
将 NVIDIA LLM API 与 Spring AI 一起使用时,请牢记以下几点:
有关更多信息,请查看 Spring AI 和 OpenAI 参考文档。
将 NVIDIA LLM API 与 Spring AI 集成,为希望在其 Spring 应用程序中利用高性能 AI 模型的开发者开辟了新的可能性。通过重用 OpenAI 客户端,Spring AI 使得在不同 AI 提供商之间切换变得简单直接,让您可以为您的特定需求选择最佳解决方案。
在您探索此集成时,请记住随时关注 Spring AI 和 NVIDIA LLM API 的最新文档,因为功能和模型的可用性可能会随时间演变。
我们鼓励您尝试不同的模型,比较它们的性能和输出,以便找到最适合您用例的模型。
祝您编程愉快,尽享 NVIDIA LLM API 为您的 AI 驱动 Spring 应用程序带来的速度和能力!